mysql回表致索引失效案例讲解
简介
mysql的innodb引擎查询记录时在无法使用索引覆盖的场景下,需要做回表操作获取记录的所需字段。
mysql执行sql前会执行sql优化、索引选择等操作,mysql会预估各个索引所需要的查询代价以及不走索引所需要的查询代价,从中选择一个mysql认为代价最小的方式进行sql查询操作。而在回表数据量比较大时,经常会出现mysql对回表操作查询代价预估代价过大而导致索引使用错误的情况。
案例
示例如下,在5.6版本的mysql、1CPU2G内存的Linux环境下,新建一个测试表,并创建将近200万的记录用于测试。
CREATE TABLE `salary_static` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增主键', `school_id` int(11) NOT NULL COMMENT '学校id', `student_id` int(11) NOT NULL COMMENT '毕业生id', `salary` int(11) NOT NULL DEFAULT '0' COMMENT '毕业薪水', `year` int(11) NOT NULL COMMENT '毕业年份', PRIMARY KEY (`id`), KEY `school_id_key` (`school_id`) USING BTREE, KEY `year_school_key` (`year`,`school_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='毕业生薪水数据统计';
delimiter // CREATE PROCEDURE init_salary_static() BEGIN DECLARE year INT; DECLARE schid INT; DECLARE stuid INT; SET year = 2000; WHILE year < 2020 DO START TRANSACTION; SET schid = 1; WHILE schid < 100 DO SET stuid = 1; WHILE stuid < 1000 DO insert into salary_static(school_id,student_id,salary,year) values (schid,stuid,floor(rand()*10000),year); SET stuid = stuid + 1; END WHILE; SET schid = schid + 1; END WHILE; SET year = year + 1; COMMIT; END WHILE; END // delimiter ; call init_salary_static();
测试数据创建完成后,执行以下sql语句进行统计查询。
select school_id,avg(salary) from salary_static where year between 2016 and 2019 group by school_id;
预计该sql应该使用year_school_key索引进行查询,但实际上通过explain命令可以发现,该sql使用的是school_id_key索引,并且由于使用了错误的索引,该sql进行了全表扫描导致查询时间花费了7秒。


强制使用year_school_key索引进行查询后发现,该sql的查询时间花费锐减到了0.6秒,比起school_id_key索引的时间减少了10倍。
select school_id,avg(salary) from salary_static force index(year_school_key) where year between 2015 and 2019 group by school_id;


分析
使用mysql的optimizer tracing(mysql5.6版本开始支持)功能来分析sql的执行计划:
SET optimizer_trace="enabled=on"; select school_id,avg(salary) from salary_static where year between 2016 and 2019 group by school_id; SELECT * FROM INFORMATION_SCHEMA.OPTIMIZER_TRACE;
输出的结果为一个json,展示了该sql在mysql内部的sql优化过程、索引选择过程的执行计划。
重点关注执行计划的json中range_analysis下的内容,这里展示了where范围查询过程中索引选择。table_scan表示全表扫描,预估需要扫描1973546条记录,但是由于全表扫描走聚集索引是顺序IO读,因此每条记录的查询成本很小,最终计算出来的查询成本为399741。range_scan_alternatives表示使用索引的范围查询,year_school_key索引预估需要扫描812174条记录,但是由于需要回表操作导致随机IO读,最终计算出来的查询成本为974610。所以对于where查询过程最终选择全表扫描不走索引。
"range_analysis": {
"table_scan": {
"rows": 1973546,
"cost": 399741
},
"potential_range_indices": [
{
"index": "PRIMARY",
"usable": false,
"cause": "not_applicable"
},
{
"index": "school_id_key",
"usable": true,
"key_parts": [
"school_id",
"id"
]
},
{
"index": "year_school_key",
"usable": true,
"key_parts": [
"year",
"school_id",
"id"
]
}
],
"setup_range_conditions": [
],
"group_index_range": {
"chosen": false,
"cause": "not_applicable_aggregate_function"
},
"analyzing_range_alternatives": {
"range_scan_alternatives": [
{
"index": "year_school_key",
"ranges": [
"2016 <= year <= 2019"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 812174,
"cost": 974610,
"chosen": false,
"cause": "cost"
}
],
"analyzing_roworder_intersect": {
"usable": false,
"cause": "too_few_roworder_scans"
}
}
}
这里的查询成本cost值完全可以手算出来,cost=I/O成本(每一次读取记录页一次成本,每次成本为1.0)+CPU成本(每一条记录一次成本,每次成本为0.2)。
全表扫描查询成本
table_scan全表扫描时预估需要扫描1973546条记录,通过show table status like "salary_static"命令可得全表记录为82411520字节(Data_length),innodb每个记录页为16KB即全表扫描需要读取82411520/1024/16 = 5030个记录页。
- I/O成本
5030 * 1.0 = 5030
- CPU成本
1973546 * 0.2 = 394709.2
- 合计查询成本
5030 + 394709.2 = 399739.2
索引查询成本
year_school_key索引时预估需要扫描812174条记录,且使用该索引需要先通过索引查询到rowId,然后通过rowId回表。mysql认为每次回表均需要一次单独的I/O成本
- CPU成本
812174 * 0.2 = 162434.8
- I/O成本
812174 * 1.0 = 812174
- 合计查询成本
162434.8 + 812174 = 974608.8
接着再关注reconsidering_access_paths_for_index_ordering,表示最终对排序再进行一次索引选择优化。这里选择了school_id_key索引并且一票否决了上面where条件选择的全表扫描:"plan_changed": true,详见group-by-optimization。
{
"reconsidering_access_paths_for_index_ordering": {
"clause": "GROUP BY",
"index_order_summary": {
"table": "`salary_static`",
"index_provides_order": true,
"order_direction": "asc",
"index": "school_id_key",
"plan_changed": true,
"access_type": "index_scan"
}
}
}
事实上排序索引优化也存在bug,详见Bug#93845。
优化
通过分析sql执行过程,可以发现选择索引错误的是因为year_school_key索引回表记录太多导致预估查询成本大于全表扫描最终选择了错误的索引。
因此减少该sql的执行时间,下一步的优化方案是减少该sql的回表操作,即让该sql进行索引覆盖。该sql涉及到的字段只有school_id、salary和year这3个字段,因此创建这3个索引的联合索引,并注意这3个字段在联合索引中的顺序:where过滤语句最先执行,所以year字段在联合索引第一位;group by语句本质上和order by一样,因此排在where后面即联合索引第二位;salary仅仅为了减少回表因此放在联合索引末位。
CREATE INDEX year_school_salary_key ON salary_static (year, school_id, salary);
在创建了联合索引后,再执行sql语句后效果如下,仅花费了0.2秒完成查询,比起school_id_key索引的时间减少了35倍。

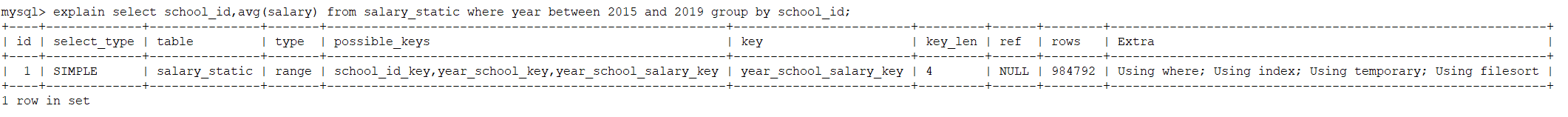
回表率计算
上述问题为sql一次性查询数量太多,导致回表代价太大。事实上,上述现象的临界值完全可以计算出来:
假设一行记录的大小为a字节,表的记录数量为b,临界记录数量为c,则该表的记录页数量为b*a/1024/16
全表扫描的查询成本 = I/O成本 + CPU成本 = b*a/1024/16 * 1.0 + b * 0.2 索引扫描的查询成本 = I/O成本 + CPU成本 = c * 1.0 + c * 0.2 = c * 1.2 b*a/1024/16 * 1.0 + b * 0.2 = c * 1.2 临界比例 = c/b = (a/1024/16 + 0.2)/1.2 = a * 5E-5 + 0.1667
即当一条sql查询超过表中超过大概17%的记录且不能使用覆盖索引时,会出现索引的回表代价太大而选择全表扫描的现象。且这个比例随着单行记录的字节大小的增加而略微增大。
到此这篇关于mysql回表致索引失效案例讲解的文章就介绍到这了,更多相关mysql回表致索引失效内容请搜索猪先飞以前的文章或继续浏览下面的相关文章希望大家以后多多支持猪先飞!
相关文章
- 这篇文章主要介绍了MySQL性能监控软件Nagios的安装及配置教程,这里以CentOS操作系统为环境进行演示,需要的朋友可以参考下...2015-12-14
- 新版 Mysql 中加入了对 JSON Document 的支持,可以创建 JSON 类型的字段,并有一套函数支持对JSON的查询、修改等操作,下面就实际体验一下...2016-08-23
深入研究mysql中的varchar和limit(容易被忽略的知识)
为什么标题要起这个名字呢?commen sence指的是那些大家都应该知道的事情,但往往大家又会会略这些东西,或者对这些东西一知半解,今天我总结下自己在mysql中遇到的一些commen sense类型的问题。 ...2015-03-15- 这篇文章主要介绍了MySQL 字符串拆分操作(含分隔符的字符串截取),具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-02-22
- 联合索引又叫复合索引。对于复合索引:Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。例如索引是key index (a,b,c). 可以支持a | a,b| a,b,c 3种组合进行查找,但不支持 b,c进...2015-11-24
- 一、先说一下为什么要分表:当一张的数据达到几百万时,你查询一次所花的时间会变多,如果有联合查询的话,有可能会死在那儿了。分表的目的就在于此,减小数据库的负担,缩短查询时间。根据个人经验,mysql执行一个sql的过程如下:1...2014-05-31
- 我们自己鼓捣mysql时,总免不了会遇到这个问题:插入中文字符出现乱码,虽然这是运维先给配好的环境,但是在自己机子上玩的时候咧,总得知道个一二吧,不然以后如何优雅的吹牛B。...2015-03-15
- 这篇文章主要介绍了node.js如何操作MySQL数据库,帮助大家更好的进行web开发,感兴趣的朋友可以了解下...2020-10-29
- 这几天在centos下装mysql,这里记录一下安装的过程,方便以后查阅Mysql5.5.37安装需要cmake,5.6版本开始都需要cmake来编译,5.5以后的版本应该也要装这个。安装cmake复制代码 代码如下: [root@local ~]# wget http://www.cm...2015-03-15
- 宿主机使用网线的时候,客户机在Bridged Adapter模式下,使用Atheros AR8131 PCI-E Gigabit Ethernet Controller上网没问题。 宿主机使用无线的时候,客户机在Bridged Adapter模式下,使用可选项里唯一一个WIFI选项,Microsoft Virtual Wifi Miniport Adapter也无法上网,故弃之。...2013-09-19
- 首先要声明一点,大部分情况下,修改MySQL密码是需要有mysql里的root权限的...2013-09-11
- MySQL命令行导出数据库: 1,进入MySQL目录下的bin文件夹:cd MySQL中到bin文件夹的目录 如我输入的命令行:cd C:/Program Files/MySQL/MySQL Server 4.1/bin (或者直接将windows的环境变量path中添加该目录) ...2013-09-26
- 一、连接Mysql格式: mysql -h主机地址 -u用户名 -p用户密码1、连接到本机上的MYSQL。首先打开DOS窗口,然后进入目录mysql/bin,再键入命令mysql -u root -p,回车后提示你输密码.注意用户名前可以有空格也可以没有空格,但是密...2015-11-08
- Navicat for MySQL注册码用来激活 Navicat for MySQL 软件,只要拥有 Navicat 注册码就能激活相应的 Navicat 产品。这篇文章主要介绍了Navicat for MySQL 11注册码\激活码汇总,需要的朋友可以参考下...2020-11-23
- 这篇文章主要介绍了mysql IS NULL使用索引案例讲解,本篇文章通过简要的案例,讲解了该项技术的了解与使用,以下就是详细内容,需要的朋友可以参考下...2021-08-14
- 索引并不是时时都会生效的,比如以下几种情况,将导致索引失效: 1.如果条件中有or,即使其中有条件带索引也不会使用(这也是为什么尽量少用or的原因) 注意:要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引 ...2014-06-07
- 一、准备编译环境,安装所需依赖包yum groupinstall 'Development' -y yum install openssl openssl-devel zlib zlib-devel -y yum install readline-devel pcre-devel ncurses-devel bison-devel cmake -y二、编译安...2015-10-21
- 这篇文章主要介绍了基于PostgreSQL和mysql数据类型对比兼容,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-12-25
Mysql中 show table status 获取表信息的方法
这篇文章主要介绍了Mysql中 show table status 获取表信息的方法的相关资料,需要的朋友可以参考下...2016-03-12- mysql 唯一索引UNIQUE一般用于不重复数据字段了我们经常会在数据表中的id设置为唯一索引UNIQUE,下面我来介绍如何在mysql中使用唯一索引UNIQUE吧。 创建唯一索引的目的不是为了提高访问速度,而只是为了避免数据出现重复...2015-11-24