php用正则判断是否为中文例子
php用preg_match来匹配并判断一个字符串中是否含有中文或者都是中文的方法如下:
$str = 'php学习博客';
if(preg_match('/[\x7f-\xff]/', $str)){
echo '字符串中有中文<br/>';
}else{
echo '字符串中没有中文<br/>';
}
if(preg_match('/^[\x7f-\xff]+$/', $str)){
echo '字符串全是中文';
}else{
echo '字符串不全是中文';
}
以上程序的输出的结果为:
字符串中有中文
字符串不全是中文
utf-8和gbk编码下都进行了一番测试,均可以使用。
补充:
$str="aaa";
if(!eregi("[^\x80-\xff]","$str"))
{
echo "是";
}
else
{
echo "不是";
}
?>
";
//if (preg_match("/^[".chr(0xa1)."-".chr(0xff)."]+$/", $str)) { //只能在GB2312情况下使用
if (preg_match("/^[\x7f-\xff]+$/", $str)) { //兼容gb2312,utf-8
echo "正确输入";
} else {
echo "错误输入";
}
?>
如果想判断一个字符串内是否有含有中文,请用下面的代码:
if (preg_match("/[\x7f-\xff]/", $string)) {
echo "有中文";
}else{
echo "没有中文";
}
判断中文和编码有关 gbk是双字节,utf8是三字节,可以根据中文的范围来判断
编码范围1. GBK (GB2312/GB18030)
\x00-\xff GBK双字节编码范围
\x20-\x7f ASCII
\xa1-\xff 中文
\x80-\xff 中文
2. UTF-8 (Unicode)
\u4e00-\u9fa5 (中文)
\x3130-\x318F (韩文
\xAC00-\xD7A3 (韩文)
\u0800-\u4e00 (日文)
ps: 韩文是大于[\u9fa5]的字符
正则例子:
preg_replace(”/([\x80-\xff])/”,”",$str);
preg_replace(”/([u4e00-u9fa5])/”,”",$str);
今天深入的把正则表达式看了一下,总结一下php的正则表达式所使用的函数
preg_match();
preg_match_all();
preg_replace();
preg_filter();
preg_grep();
preg_split();
preg_quote();
基本有这么多吧。
一个个来
先给大家介绍一个 在线 验证 正则表达式的工具
http://regexpal.isbadguy.com/
打开你就明白怎吗用了,我们先来说
preg_match() 函数用于进行正则表达式匹配,成功返回 1 ,否则返回 0 。
这个很简单直接来个例子就明白了
$subject = "abcdef";
$pattern = '/^def/';
preg_match($pattern, $subject, $matches, PREG_OFFSET_CAPTURE, 3);
print_r($matches);
preg_match_all() 函数用于进行正则表达式全局匹配,成功返回整个模式匹配的次数(可能为零),如果出错返回 FALSE 。
preg_match_all("|<[^>]+>(.*)</[^>]+>|U",
"<b>example: </b><div align=left>this is a test</div>",
$out, PREG_PATTERN_ORDER);
echo $out[0][0] . ", " . $out[0][1] . "\n";
echo $out[1][0] . ", " . $out[1][1] . "\n";
我们来重点讲讲
preg_replace();
preg_filter();
这两个函数的区别
$subject = array('1', 'a', '2', 'b', '3', 'A', 'B', '4');
$pattern = array('/d/', '/[a-z]/', '/[1a]/');
$replace = array('A:$0', 'B:$0', 'C:$0');
echo "preg_filter returns ";
print_r(preg_filter($pattern, $replace, $subject));
echo "preg_replace returns ";
print_r(preg_replace($pattern, $replace, $subject));
很明显我们可以看一下结果
preg_filter returns Array
(
[0] => C:1
[1] => B:C:a
[3] => B:b
)
preg_replace returns Array
(
[0] => C:1
[1] => B:C:a
[2] => 2
[3] => B:b
[4] => 3
[5] => A
[6] => B
[7] => 4
)
这样就很明显了,preg_filter不会保留不匹配的选项,而preg_replace会保留不匹配的选项
preg_grep — 返回匹配模式的数组条目
$array = array("23.32","22","12.009","23.43.43");
print_r(preg_grep("/^(\d+)?\.\d+\.\d+$/",$array));
preg_split — 通过一个正则表达式分隔字符串
这个函数要提得一点是,explode()可以算是这个函数的一个子集
preg_quote — 转义正则表达式字符
最后这个函数就没什么好讲的了。就是不让执行正则表达式,转义一下字符,和自己手动加\转移是一样的
邮箱验证使用正则是非常的简单了,我们这里整理了两种PHP用户注册邮箱验证正则表达式方法例子,希望此文章能够让各位有帮助.
| 代码如下 | 复制代码 |
preg_match("/^[0-9a-zA-Z]+@(([0-9a-zA-Z]+)[.])+[a-z]{2,4}$/i",$email );
| |
| 代码如下 | 复制代码 |
<?php
function isEmail($email){ if(preg_match("/^[0-9a-zA-Z]+@(([0-9a-zA-Z]+)[.])+[a-z]{2,4}$/i",$email )){ return '是邮箱'; } return '不是邮箱'; } } ?> | |
| 代码如下 | 复制代码 |
if(!preg_match("/^[0-9a-zA-Z]+@(([0-9a-zA-Z]+)[.])+[a-z]{2,4}$/i",$email )){
exit('错误:电子邮箱格式错误。<a href="javascript:history.back(-1);">返回</a>'); } | |
| 代码如下 | 复制代码 |
<script type="text/javascript">
function isEmail(val){
var myreg = /^([a-zA-Z0-9]+[_|\_|\.]?)*[a-zA-Z0-9]+@([a-zA-Z0-9]+[_|\_|\.]?)*[a-zA-Z0-9]+\.[a-zA-Z]{2,4}$/;
if(!myreg.test(val))
return '不是邮箱';
return '是邮箱';
};
alert( isEmail('i@julying.com') );
</script>
| |
将一个网页里面所有引入的js文件都匹配出来,在php中用正则表达式来实现,方式如下:
<?php
header("Content-type:text/html;charset=utf-8");
//匹配一个网页中引入的js文件
$pageContent = file_get_contents('http://www.daixiaorui.com/cat_2.html');
preg_match_all('/<script.*?src\s*=\s*[\"|\'](.*?)[\"|\'].*?>\s*?<\/script>/i', $pageContent, $js);
print_r($js);
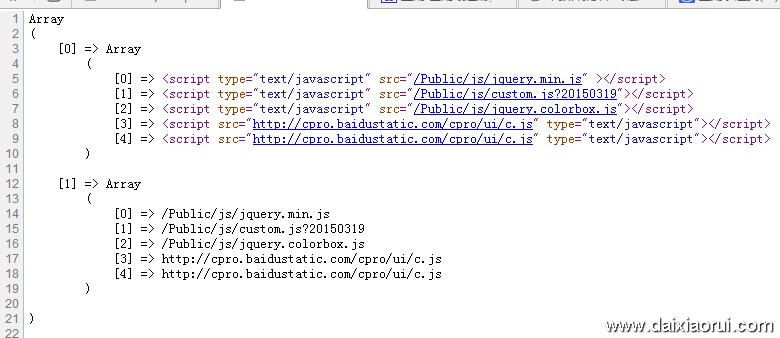
其中“src\s*=\s*”表示可以是“src=”也可以是“src = ”这样的;“[\"|\']”表示路径可以是单引号,也可以为双引号;“.*?”尽可能的少重复,匹配最近的位置。
相关文章
js URLdecode()与urlencode方法支持中文解码
下面来介绍在js中来利用urlencode对中文编码与接受到数据后利用URLdecode()对编码进行解码,有需要学习的机友可参考参考。 代码如下 复制代码 ...2016-09-20- 安装curl扩展支持https是非常的重要现在许多的网站都使用了https了,下面我们来看一篇关于PHP安装curl扩展支持https例子吧。 问题: 线上运行的lamp服务器,默认yu...2016-11-25
- 这篇文章主要给大家介绍了一个关于JS正则匹配的踩坑记录,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2021-04-13
关于Mysql中文乱码问题该如何解决(乱码问题完美解决方案)
最近两天做项目总是被乱码问题困扰着,这不刚把mysql中文乱码问题解决了,下面小编把我的解决方案分享给大家,供大家参考,也方便以后自己查阅。首先:用show variables like “%colla%”;show varables like “%char%”;这两条...2015-11-24- 这篇文章主要介绍了C#读取中文文件出现乱码的解决方法,涉及C#中文编码的操作技巧,非常具有实用价值,需要的朋友可以参考下...2020-06-25
- 我们自己鼓捣mysql时,总免不了会遇到这个问题:插入中文字符出现乱码,虽然这是运维先给配好的环境,但是在自己机子上玩的时候咧,总得知道个一二吧,不然以后如何优雅的吹牛B。...2015-03-15
- 在debian环境下,彻底解决mysql无法插入和显示中文的问题Linux下Mysql插入中文显示乱码解决方案mysql -uroot -p 回车输入密码进入mysql查看状态如下:默认的是客户端和服务器都用了latin1,所以会乱码。解决方案:mysql>use...2013-10-04
- 一.mysql默认不支持中文,它的server和db默认是latin1编码.所以我们要将其改变为utf-8编码,因为utf-8包含了地球上大部分语言的二进制编码 1.关闭mysql服务 sudo /etc/init.d/mysql stop 2.修改mysql配置文件 mysql配...2015-10-21
- 小编分享了一段简单的php中文转拼音的实现代码,代码简单易懂,适合初学php的同学参考学习。 代码如下 复制代码 <?phpfunction Pinyin($_String...2017-07-06
- 这篇文章主要介绍了Java连接数据库oracle中文乱码解决方案,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下...2020-05-16
- floor会产生小数了如果我们不希望有小数我们是可以去除小数点的了,下面一聚教程小编来为各位介绍php使用floor去掉小数点的例子,希望对各位有帮助。 float floor (...2016-11-25
- 这篇文章主要介绍了JS基于正则截取替换特定字符之间字符串操作方法,结合具体实例形式分析了JS基于正则实现针对特殊字符、数字等字符串类型的截取操作相关技巧,需要的朋友可以参考下...2017-02-08
- FlashFXP是一款常用的服务器客户连接软件了,我们可以通过FlashFXP来上传或下载文件,但有一些朋友使用FlashFXP时碰到中文目录或文件名乱码问题,那么要如何来解决呢?具体就...2016-10-10
- 关于匹配字符串问题,有很多种类型,今天讨论 js 代码里的字符串匹配,因为我想学完之后写个语法高亮练手,所以用js代码当作例子...2021-05-07
- 小编在网上看到最多的就是汉字转换unicode编码了,今天我们看到一个反过来的操作就是把unicode转换成中文了,下面一起来看看 这两天帮别人开发微信平台好友板块,存...2016-11-25
- 昨天在《js 正则学习小记之匹配字符串字面量》谈到 /"(?:\\.|[^"])*"/ 是个不错的表达式,因为可以满足我们的要求,所以这个表达式可用,但不一定是最好的...2021-05-07
- 最近在开发一个项目,其中有需求要求我们把一段html转换为一般文本返回,使用正则表达式是明智的选择,下面小编给介绍下C#使用正则表达式过滤html标签,需要的朋友参考下...2020-06-25
- 复制代码 代码如下: $str='asb天水市12'; if (preg_match("/^[/x7f-/xff]+$/", $str)){ echo '全部是汉字'; }else { echo '不全是汉字'; } /** PHP自带的判断是否是中文, eregi('[^/x00-/x7F]', $str ) //中文 ereg...2013-10-04
- 这篇文章主要介绍JS正则RegExp对象,正则表达式是描述字符模式的对象,用于对字符串模式匹配及检索替换,是对字符串执行模式匹配的强大工具。下面就来看具体详情,需要的朋友可以参考一下...2021-10-21
- 在 OpenResty 中,同时存在两套正则表达式规范:Lua 语言的规范和 Nginx 的规范,下面这篇文章主要给大家介绍了关于OpenResty中正则模式匹配的2种方法,文中通过示例代码介绍的非常详细,需要的朋友可以参考下。...2020-06-30