php与python 线程池多线程爬虫的例子
php例子
<?php
class Connect extends Worker //worker模式
{
public function __construct()
{
}
public function getConnection()
{
if (!self::$ch)
{
self::$ch = curl_init();
curl_setopt(self::$ch, CURLOPT_TIMEOUT, 2);
curl_setopt(self::$ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt(self::$ch, CURLOPT_HEADER, 0);
curl_setopt(self::$ch, CURLOPT_NOSIGNAL, true);
curl_setopt(self::$ch, CURLOPT_USERAGENT, "Firefox");
curl_setopt(self::$ch, CURLOPT_FOLLOWLOCATION, 1);
}
/* do some exception/error stuff here maybe */
return self::$ch;
}
public function closeConnection()
{
curl_close(self::$ch);
}
/**
* Note that the link is stored statically, which for pthreads, means thread local
* */
protected static $ch;
}
class Query extends Threaded
{
public function __construct($url)
{
$this->url = $url;
}
public function run()
{
$ch = $this->worker->getConnection();
curl_setopt($ch, CURLOPT_URL, $this->url);
$page = curl_exec($ch);
$info = curl_getinfo($ch);
$error = curl_error($ch);
$this->deal_data($this->url, $page, $info, $error);
$this->result = $page;
}
function deal_data($url, $page, $info, $error)
{
$parts = explode(".", $url);
$id = $parts[1];
if ($info['http_code'] != 200)
{
$this->show_msg($id, $error);
} else
{
$this->show_msg($id, "OK");
}
}
function show_msg($id, $msg)
{
echo $id."\t$msg\n";
}
public function getResult()
{
return $this->result;
}
protected $url;
protected $result;
}
function check_urls_multi_pthreads()
{
global $check_urls; //定义抓取的连接
$check_urls = array( 'http://xxx.com' => "xx网",);
$pool = new Pool(10, "Connect", array()); //建立10个线程池
foreach ($check_urls as $url => $name)
{
$pool->submit(new Query($url));
}
$pool->shutdown();
}
check_urls_multi_pthreads();
python 多线程
def handle(sid)://这个方法内执行爬虫数据处理
pass
class MyThread(Thread):
"""docstring for ClassName"""
def __init__(self, sid):
Thread.__init__(self)
self.sid = sid
def run():
handle(self.sid)
threads = []
for i in xrange(1,11):
t = MyThread(i)
threads.append(t)
t.start()
for t in threads:
t.join()
python 线程池爬虫
from queue import Queue
from threading import Thread, Lock
import urllib.parse
import socket
import re
import time
seen_urls = set(['/'])
lock = Lock()
class Fetcher(Thread):
def __init__(self, tasks):
Thread.__init__(self)
self.tasks = tasks
self.daemon = True
self.start()
def run(self):
while True:
url = self.tasks.get()
print(url)
sock = socket.socket()
sock.connect(('localhost', 3000))
get = 'GET {} HTTP/1.0\r\nHost: localhost\r\n\r\n'.format(url)
sock.send(get.encode('ascii'))
response = b''
chunk = sock.recv(4096)
while chunk:
response += chunk
chunk = sock.recv(4096)
links = self.parse_links(url, response)
lock.acquire()
for link in links.difference(seen_urls):
self.tasks.put(link)
seen_urls.update(links)
lock.release()
self.tasks.task_done()
def parse_links(self, fetched_url, response):
if not response:
print('error: {}'.format(fetched_url))
return set()
if not self._is_html(response):
return set()
urls = set(re.findall(r'''(?i)href=["']?([^\s"'<>]+)''',
self.body(response)))
links = set()
for url in urls:
normalized = urllib.parse.urljoin(fetched_url, url)
parts = urllib.parse.urlparse(normalized)
if parts.scheme not in ('', 'http', 'https'):
continue
host, port = urllib.parse.splitport(parts.netloc)
if host and host.lower() not in ('localhost'):
continue
defragmented, frag = urllib.parse.urldefrag(parts.path)
links.add(defragmented)
return links
def body(self, response):
body = response.split(b'\r\n\r\n', 1)[1]
return body.decode('utf-8')
def _is_html(self, response):
head, body = response.split(b'\r\n\r\n', 1)
headers = dict(h.split(': ') for h in head.decode().split('\r\n')[1:])
return headers.get('Content-Type', '').startswith('text/html')
class ThreadPool:
def __init__(self, num_threads):
self.tasks = Queue()
for _ in range(num_threads):
Fetcher(self.tasks)
def add_task(self, url):
self.tasks.put(url)
def wait_completion(self):
self.tasks.join()
if __name__ == '__main__':
start = time.time()
pool = ThreadPool(4)
pool.add_task("/")
pool.wait_completion()
print('{} URLs fetched in {:.1f} seconds'.format(len(seen_urls),time.time() - start))

有朋友在阿里云主机实现微信支付逻辑时,发现api.mch.weixin.qq.com的解析实在是太慢了。
因此出现了手动修改/etc/hosts的情况,当然了,哪天微信支付要是换个机房肯定要挂。
我们的机房也有相似的同题,专门记录一下。
代码里用curl来请求微信,经常超时,这时使用wget试验:
[root@01 tmp]# wget api.mch.weixin.qq.com
--2016-06-18 14:51:03-- http://api.mch.weixin.qq.com/
Resolving api.mch.weixin.qq.com... 域名解析很久不出来
测试确认是ipv6问题
给wget加上-4,强制使用ipv4,如果很快,那基本上确定是ipv6惹的祸了。
[root@01 tmp]# wget -4 api.mch.weixin.qq.com
--2016-06-18 17:03:52-- http://api.mch.weixin.qq.com/
Resolving api.mch.weixin.qq.com... 123.151.71.149, 123.151.79.109
Connecting to api.mch.weixin.qq.com|123.151.71.149|:80... connected.
代码分析
专门写个代码来测试ipv6的解析,用到系统函数getaddrinfo:
#include <stdio.h>
#include <string.h>
#include <netdb.h>
#include <iostream>
#include <sys/types.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <arpa/inet.h>
using namespace std;
int main() {
struct addrinfo hints,*answer,*curr,*p;
int error;
memset(&hints, 0, sizeof hints);
hints.ai_family = AF_INET6;//AF_UNSPEC; // use AF_INET6 to force IPv6
hints.ai_socktype = SOCK_STREAM;//SOCK_DGRAM; // SOCK_STREAM
if ((error = getaddrinfo("api.mch.weixin.qq.com", NULL, &hints, &answer)) != 0) {
fprintf(stderr, "getaddrinfo: %s\n", gai_strerror(error));
return 1;
} else cout <<"Success with a URL\n";
char ipstr[16];
for (curr = answer; curr != NULL; curr = curr->ai_next) {
inet_ntop(AF_INET,&(((struct sockaddr_in *)(curr->ai_addr))->sin_addr),ipstr, 16);
printf("%s\n", ipstr);
}
freeaddrinfo(answer);
return 0;
}
包含头文件
netdb.h
函数原型
int getaddrinfo( const char hostname, const char service, const struct addrinfo *hints, struct addrinfo **result );
参数说明
hints:可以是一个空指针,也可以是一个指向某个addrinfo结构体的指针,调用者在这个结构中填入关于期望返回的信息类型的暗示。举例来说:如果指定的服务既支持TCP也支持UDP,那么调用者可以把hints结构中的ai_socktype成员设置成SOCK_DGRAM使得返回的仅仅是适用于数据报套接口的信息。而是否ipv6则由ai_family决定。
result:本函数通过result指针参数返回一个指向addrinfo结构体链表的指针。
返回值:0——成功,非0——出错
测试结果
ai_family为ipv6时,只会寻找ipv6的解析结果,一般域名也没设置。ai_family为AF_UNSPEC时,会先ipv6再ipv4的,而api.mch.weixin.qq.com这个域名的ipv6解析出奇的慢(qq.com却不慢,原因见后)。
解决办法
如果是curl,c可以强制指定ipv4,使用curl_easy_setopt(curl, CURLOPT_IPRESOLVE, CURL_IPRESOLVE_V4);
其他语言的也参考此法。
测试代码下载
深层原因分析
nslookup -query=AAAA api.mch.weixin.qq.com -debug 是找不到解析的(指定的AAAA就是ipv6),然后会发现一个SOA声明和他的上级weixin.qq.com有一个ipv6的CNAME,到了minorshort.weixin.qq.com,而这域名又是没有ipv6的解析的。
目测ipv6找解析时是在这个SOA和CNAME的地方打圈了,微信的同学们是不是考虑让大伙好过一点,把这些个域名的ipv6设置去掉。
dig @ns-tel1.qq.com weixin.qq.com AAAA
weixin.qq.com. 43200 IN SOA ns-tel1.qq.com. webmaster.qq.com. 1293502040 300 600 86400 300
XHProf是一个分层PHP性能分析工具。XHProf是一个分层PHP性能分析工具。它报告函数级别的请求次数和各种指标,包括阻塞时间,CPU时间和内存使用情况,下面我们来看PHP性能分析工具XHProf深入分析吧。
常见问题
多次调用xhprof_enable方法,最后生效的配置是哪个?
当你在一次请求中多次调用xhprof_enable方法,只有第一次调用时进行的设置能生效。在调用
xhprof_disable()后,你又可以使用xhprof_enable方法进行设置。
$i = 0;
function good(){
global $i;
$i++;
if ($i < 2) {
good();
}
}
function func() {
good();
}
$start_time = microtime(true);
xhprof_enable(XHPROF_FLAGS_NO_BUILTINS);
xhprof_enable(XHPROF_FLAGS_MEMORY + XHPROF_FLAGS_CPU + XHPROF_FLAGS_NO_BUILTINS);
for ($i = 0; $i < 100; $i++) {
func();
}
good();
$rst = xhprof_disable();
var_dump($rst);
输出内容为:
array(5) {
["good==>good@1"]=>
array(2) {
["ct"]=>
int(1)
["wt"]=>
int(70)
}
["func==>good"]=>
array(2) {
["ct"]=>
int(50)
["wt"]=>
int(121)
}
["main()==>func"]=>
array(2) {
["ct"]=>
int(50)
["wt"]=>
int(135)
}
["main()==>good"]=>
array(2) {
["ct"]=>
int(1)
["wt"]=>
int(0)
}
["main()"]=>
array(2) {
["ct"]=>
int(1)
["wt"]=>
int(237)
}
}
可见,打印的内容,并没有cpu和memory的信息。
输出内容中的ct,wt,cpu,mu, pmu 都代表什么意思
ct 表示 调用的次数
wt 表示 函数方法执行的时间耗时。相当于,在调用前记录一个时间,函数方法调用完毕后,计算时间差。
cpu 表示 函数方法执行消耗的cpu时间。和wt的差别在于,当进程让出cpu使用权后,将不再计算cpu时间。通过调用系统调用getrusage获取进程的占用cpu数据。
mu 表示 函数方法所使用的内存。相当于,在调用前记录一个内存占用,函数方法调用完毕后,计算内存差。调用的是zend_memory_usage获取内存占用情况。
pmu 表示 函数方法所使用的内存峰值。调用的是zend_memory_peak_usage获取内存情况。
输出内容中good==>good@1 是什么意思
==>表示一个调用关系。由于带@,说明是一个递归调用。@后面的数字是递归调用的深度。
如何设置xhprof_enable的参数,减少性能消耗
xhprof_enable提供了三个常量,用于设置你是否需要统计PHP内置函数,都统计那些指标。
三个常量如下:
XHPROF_FLAGS_NO_BUILTINS
设置这个常量后,将不统计PHP内置函数。毕竟PHP的内置函数性能一般都不错。没必要再消耗性能去统计。所以,建议设置。
XHPROF_FLAGS_CPU
设置这个常量后,会统计进程占用CPU时间。由于CPU时间是通过调用系统调用getrusage获取,导致性能比较差。开启这个选项后,大概性能下降一半。因此,如果对cpu耗时不是特别敏感的情况下,建议不要启用这个选项。
XHPROF_FLAGS_MEMORY
设置这个常量后,将会统计内存占用情况。由于获取内存情况,使用的是zend_memory_usage和zend_memory_peak_usage,并不是系统调用。因此,对性能影响不大。如果需要对内存使用情况进行分析的情况下,可以开启。
性能分析原理
如何实现对各个函数方法性能数据记录
目前xhprof会对,加载PHP文件,执行PHP函数方法,和执行eval方法进行性能数据记录。正好,这些在PHP内核中,有对应的函数进行处理。当你调用xhprof_enable方法时,会把默认的方法替换为xhprof的方法。来看看相关代码吧。
static void hp_begin(long level, long xhprof_flags)
{
if (!hp_globals.enabled)
{
int hp_profile_flag = 1;
hp_globals.enabled = 1;
hp_globals.xhprof_flags = (uint32) xhprof_flags;
/* Replace zend_compile with our proxy */
/* 处理加载PHP文件 */
/* 先把zend引擎默认处理方法保存到_zend_compile_file变量中。*/
_zend_compile_file = zend_compile_file;
/* 在把xhprof相对应的方法赋值给zend_compile_file。
这样,每次加载PHP文件时,就会执行xhprof相应的方法。*/
zend_compile_file = hp_compile_file;
/* Replace zend_compile_string with our proxy */
/* 处理eval代码的执行 */
_zend_compile_string = zend_compile_string;
zend_compile_string = hp_compile_string;
/*init the execute pointer*/
/* 处理 函数方法的执行 */
_zend_execute_ex = zend_execute_ex;
zend_execute_ex = hp_execute_ex;
.........
}
}
/*那我们看下,hp_compile_file方法,又是如何实现的*/
ZEND_DLEXPORT zend_op_array* hp_compile_file(zend_file_handle *file_handle, int type)
{
const char *filename;
char *func;
int len;
zend_op_array *ret;
int hp_profile_flag = 1;
filename = hp_get_base_filename(file_handle->filename);
len = sizeof("load") - 1 + strlen(filename) + 3;
func = (char *) emalloc(len);
snprintf(func, len, "load::%s", filename);
//方法执行前记录当前各项性能如数,如cpu 内存等
BEGIN_PROFILING(&hp_globals.entries, func, hp_profile_flag);
//开始zend引擎相应的方法,加载文件
ret = _zend_compile_file(file_handle, type);
if (hp_globals.entries)
{
//加载文件完毕后,再次记录当前各项性能数据。以便以后计算差值。
END_PROFILING(&hp_globals.entries, hp_profile_flag);
}
efree(func);
return ret;
}
xhprof在实现的时候,性能方面做了哪些优化
获取时间时,为了性能,使用了汇编来获取时间戳计数器。时间秒 = 时间戳计数器值 / CPU主频。
正是这种实现,导致目前xhprof还只适用于x86架构。此外,因为RDTSC的数据不能在CPU间同步,所以,xhprof会将进程绑定在单个CPU上。
如果SpeedStep技术是打开的,XHProf的基于RDTSC定时器的功能就不能正常工作了。这项技术在某些英特尔处理器上是可用的。[注:苹果台式机和笔记本电脑一般都将SpeedStep技术预设开启。使用XHProf,您需要禁用SpeedStep技术。 ]
inline uint64 cycle_timer()
{
uint32 __a, __d;
uint64 val;
asm volatile("rdtsc" : "=a" (__a), "=d" (__d));
(val) = ((uint64) __a) | (((uint64) __d) << 32);
return val;
}
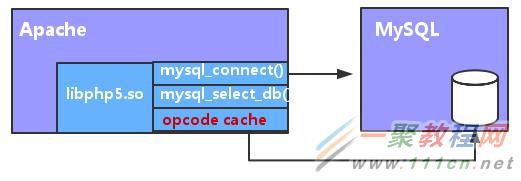
PHP服务缓存优化原理
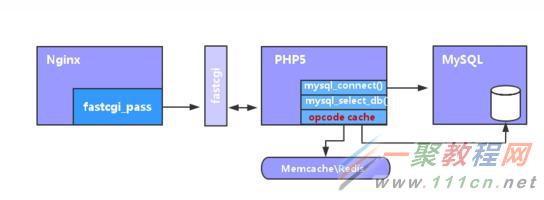
Nginx 根据扩展名或者过滤规则将PHP程序请求传递给解析PHP的FCGI,也就是php-fpm进程
缓存操作码(opcode)
Opcode,PHP编译后的中间文件,缓存给用户访问
当客户端请求一个PHP程序时,服务器的PHP引擎会解析该PHP程序,并将其编译为特定的操作码文件,该文件是执行PHP代码后的一种二进制文件表现形式。默认情况下,这个编译好的操作码文件由PHP引擎执行后丢弃;而操作码缓存的原理就是将编译后的操作码保存下来,并放入到共享内存里,以便再下一次调用该PHP页面时重用它,避免了相同代码的重复编译。节省了PHP引擎重复编译的时间,降低了服务器负载,同时减少了CPU和内存的开销.
常用的PHP缓存加速软件
1)xcache
经测试,xcache效率更好、社区活跃、兼容PHP版本多
2)ZendOpcache
Apache公司自主研发软件,5.5版本以后自带,加enbale-opcache编译参数直接使用,但是软件稳定性有待检测
3)eAccelerator
5.3版本以前经常使用的加速软件,随着5.5版本升级,和xcache等优秀软件的出现,社区活跃度开始下降
缓存软件首选xcahe、持续关注ZendOpcache...
xcache部署
1)下载xcache,添加为PHP扩展模块,编译安装
[root@web01 tools]# wget http://xcache.lighttpd.net/pub/Releases/3.2.0/xcache-3.2.0.tar.bz2
[root@web01 tools]# tar xf xcache-3.2.0.tar.bz2
[root@web01 tools]# cd xcache-3.2.0
[root@web01 xcache-3.2.0]# /application/php/bin/phpize
[root@web01 xcache-3.2.0]# ./configure --enable-xcache --with-php-config=/application/php/bin/php-config
[root@web01 xcache-3.2.0]# make && make install
...
Installing shared extensions: /application/php5.5.32/lib/php/extensions/no-debug-non-zts-20121212/
Installing header files: /application/php5.5.32/include/php/
2)配置php扩展生效
[root@db02 application]# vim /application/php/lib/php.ini
extension_dir = "/application/php5.5.32/lib/php/extensions/no-debug-non-zts-20121212/"
extension = memcache.so
extension = imagick.so
extension = xcache.so
3)重启php后模块生效
[root@db02 application]# /application/php/bin/php -m|grep "XCache"
XCache
XCache Cacher
4)xcache配置文件
[root@db02 ~]# cat ~/tools/xcache-3.2.0/xcache.ini|egrep -v "^;|^ " >> /application/php/lib/php.ini
[xcache-common]
extension = xcache.so #模块
[xcache.admin]
xcache.admin.enable_auth = On #开启密码认证
xcache.admin.user = "mOo"
xcache.admin.pass = "md5 encrypted password"
[xcache]
xcache.shm_scheme = "mmap" #设置Xcache如何从系统分配共享内存
xcache.size = 60M #缓存大小,0禁止缓存
xcache.count = 1 #指定将xcache切分为多少块,建议与CPU核数相同(grep -c processor /proc/cpuinfo)
xcache.slots = 8K
xcache.ttl = 0 #设置cache对象生存期TTL,0永不过期;如果上线次数多,调小
xcache.gc_interval = 0 #回收器扫描过期的对象回收内存空间的间隔,0不扫描
xcache.var_size = 4M #变量缓存,而不是opcache缓存
xcache.var_count = 1
xcache.var_slots = 8K
xcache.var_ttl = 0
xcache.var_maxttl = 0
xcache.var_gc_interval = 300
xcache.var_namespace_mode = 0
xcache.var_namespace = ""
xcache.coredump_type = 0
5)查看PHP chache加载情况
[root@db02 ~]# /application/php/sbin/php-fpm -v
PHP 5.5.32 (fpm-fcgi) (built: Jun 29 2016 11:32:56)
Copyright (c) 1997-2015 The PHP Group
Zend Engine v2.5.0, Copyright (c) 1998-2015 Zend Technologies
with XCache v3.2.0, Copyright (c) 2005-2014, by mOo
with XCache Cacher v3.2.0, Copyright (c) 2005-2014, by mOo
6)web界面配置
[root@db02 ~]# echo -n "123456"|md5sum
e10adc3949ba59abbe56e057f20f883e -
[root@db02 ~]# cp ~/tools/xcache-3.2.0/htdocs /application/nginx/html/www/xadmin -a
[root@db02 ~]# vim /application/php/lib/php.ini
[Date]
date.timezone = Asia/Chongqing
[xcache.admin]
xcache.admin.enable_auth = On
xcache.admin.user = "admin"
xcache.admin.pass = "e10adc3949ba59abbe56e057f20f883e"
[root@db02 ~]# pkill php-fpm
[root@db02 ~]# /application/php/sbin/php-fpm
ab压力测试效果
1)未加xcache之前
[root@db02 application]# ab -n 3000 -c 100 http://10.0.0.111/test_info.php
# 3000次会话请求、100并发数
Server Software: nginx/1.6.3
Server Hostname: 10.0.0.111
Server Port: 80
Document Path: /test_info.php #测试页面
Document Length: 83921 bytes #页面大小
Concurrency Level: 100 #100并发数
Time taken for tests: 7.973 seconds #整个测试持续时间
Complete requests: 3000 #完成的请求总数
Failed requests: 302 #失败的请求次数
(Connect: 0, Receive: 0, Length: 302, Exceptions: 0)
Write errors: 0
Total transferred: 252203675 bytes #整个过程的网络传输量
HTML transferred: 251762675 bytes #HTML内容传输量
Requests per second: 376.25 [#/sec] (mean) #吞吐量,每秒能够处理的并发数
Time per request: 265.779 [ms] (mean) #平均事务响应时间
Time per request: 2.658 [ms] (mean, across all concurrent requests)
#每个连接请求实际运行时间
Transfer rate: 30889.42 [Kbytes/sec] received
#平均每秒网络上的流量,可以帮助排除是否存在网络流量大导致响应时间延长的问题
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 1 3.2 0 21
Processing: 14 261 32.2 261 331
Waiting: 2 260 32.4 260 331
Total: 29 261 29.9 261 331
Percentage of the requests served within a certain time (ms)
50% 261
66% 268
75% 273
80% 276
90% 287 #90%的请求任务在287ms内完成
95% 303
98% 315
99% 322
100% 331 (longest request)
2)配置xache之后
[root@db02 application]# ab -n 3000 -c 100 http://10.0.0.111/test_info.php
Server Software: nginx/1.6.3
Server Hostname: 10.0.0.111
Server Port: 80
Document Path: /test_info.php
Document Length: 172 bytes
Concurrency Level: 100
Time taken for tests: 0.516 seconds
Complete requests: 3000
Failed requests: 0
Write errors: 0
Non-2xx responses: 3000
Total transferred: 969000 bytes
HTML transferred: 516000 bytes
Requests per second: 5819.42 [#/sec] (mean) #并发数上升为5000+
Time per request: 17.184 [ms] (mean)
Time per request: 0.172 [ms] (mean, across all concurrent requests)
Transfer rate: 1835.62 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 1.3 0 9
Processing: 6 17 2.1 16 21
Waiting: 0 17 2.2 16 21
Total: 7 17 1.6 16 21
Percentage of the requests served within a certain time (ms)
50% 16
66% 17
75% 18
80% 19
90% 19
95% 19
98% 20
99% 21
100% 21 (longest request)
由于是虚机测试环境,不一定十分准确,未安装xcache并发数在400-500,安装后并发数在5000左右,缓存效果提升10倍以上...
相关文章
C# WinForm多线程解决界面卡死问题的完美解决方案,使用BeginInvoke
问题描述:当我们的界面需要在程序运行中不断更新数据时,当一个textbox的数据需要变化时,为了让程序执行中不出现界面卡死的现像,最好的方法就是多线程来解决一个主线程来创建界...2020-06-24基于springcloud异步线程池、高并发请求feign的解决方案
这篇文章主要介绍了基于springcloud异步线程池、高并发请求feign的解决方案,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-02-25- 安装curl扩展支持https是非常的重要现在许多的网站都使用了https了,下面我们来看一篇关于PHP安装curl扩展支持https例子吧。 问题: 线上运行的lamp服务器,默认yu...2016-11-25
- 这篇文章主要介绍了c# 多线程处理多个数据的方法,帮助大家更好的理解和学习使用c#,感兴趣的朋友可以了解下...2021-03-31
- 这篇文章主要介绍了C#基于委托实现多线程之间操作的方法,实例分析了C#的委托机制与多线程交互操作的相关技巧,具有一定参考借鉴价值,需要的朋友可以参考下...2020-06-25
- 这篇文章主要介绍了C#多线程中的异常处理操作,涉及C#多线程及异常的捕获、处理等相关操作技巧,需要的朋友可以参考下...2020-06-25
- 这篇文章主要介绍了C#中异步和多线程的相关资料,帮助大家更好的理解和学习c#,感兴趣的朋友可以了解下...2021-01-16
- 多线程和异步操作两者都可以达到避免调用线程阻塞的目的,从而提高软件的可响应性。甚至有些时候我们就认为多线程和异步操作是等同的概念。但是,多线程和异步操作还是有一些区别的。而这些区别造成了使用多线程和异步操作的时机的区别...2020-06-25
- 这篇文章主要介绍了Java线程池中的各个参数如何合理设置操作,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教...2021-06-19
- 这篇文章主要为大家详细介绍了C#多线程之Thread类,具有一定的参考价值,感兴趣的小伙伴们可以参考一下...2020-06-25
- 在Java中,我们可以利用多线程来最大化地压榨CPU多核计算的能力,下面这篇文章主要给大家介绍了关于java中多线程与线程池基本使用的相关资料,需要的朋友可以参考下...2021-09-13
- floor会产生小数了如果我们不希望有小数我们是可以去除小数点的了,下面一聚教程小编来为各位介绍php使用floor去掉小数点的例子,希望对各位有帮助。 float floor (...2016-11-25
- 第一种解决方案的原理是:将线程执行的方法和参数都封装到一个类里面。通过实例化该类,方法就可以调用属性来实现间接的类型安全地传递多个参数...2020-06-25
- 这篇文章主要介绍了教你如何监控 Java 线程池运行状态的操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-02-27
- 在本篇文章里小编给大家整理的是一篇关于java多线程中执行多个程序的实例分析内容,有需要的朋友们可以学习参考下。...2021-02-07
- 这篇文章主要介绍了C#多线程编程中异步多线程的实现及线程池的使用,同时对多线程的一般概念及C#中的线程同步并发编程作了讲解,需要的朋友可以参考下...2020-06-25
- 这篇文章主要介绍了Springboot实现多线程注入bean的工具类操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-08-27
- th.IsBackground = true解决线程问题,意思就是把线程设置为后台线程,感兴趣的朋友可以多了解下,如何有什么妙招还请多多指导哈...2020-06-25
- 这篇文章主要介绍了C#多线程编程中的锁系统(三),本本文主要说下基于内核模式构造的线程同步方式、事件、信号量以及WaitHandle、AutoResetEvent、ManualResetEvent等内容,需要的朋友可以参考下...2020-06-25
- 这篇文章主要给大家介绍了关于Java多线程实现简易微信发红包的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2021-02-01