pandas数据的合并与拼接的实现
Pandas包的merge、join、concat方法可以完成数据的合并和拼接,merge方法主要基于两个dataframe的共同列进行合并,join方法主要基于两个dataframe的索引进行合并,concat方法是对series或dataframe进行行拼接或列拼接。
1. Merge方法
pandas的merge方法是基于共同列,将两个dataframe连接起来。merge方法的主要参数:
- left/right:左/右位置的dataframe。
- how:数据合并的方式。left:基于左dataframe列的数据合并;right:基于右dataframe列的数据合并;outer:基于列的数据外合并(取并集);inner:基于列的数据内合并(取交集);默认为'inner'。
- on:用来合并的列名,这个参数需要保证两个dataframe有相同的列名。
- left_on/right_on:左/右dataframe合并的列名,也可为索引,数组和列表。
- left_index/right_index:是否以index作为数据合并的列名,True表示是。
- sort:根据dataframe合并的keys排序,默认是。
- suffixes:若有相同列且该列没有作为合并的列,可通过suffixes设置该列的后缀名,一般为元组和列表类型。
merges通过设置how参数选择两个dataframe的连接方式,有内连接,外连接,左连接,右连接,下面通过例子介绍连接的含义。
1.1 内连接
how='inner',dataframe的链接方式为内连接,我们可以理解基于共同列的交集进行连接,参数on设置连接的共有列名。
# 单列的内连接
# 定义df1
import pandas as pd
import numpy as np
df1 = pd.DataFrame({'alpha':['A','B','B','C','D','E'],'feature1':[1,1,2,3,3,1],
'feature2':['low','medium','medium','high','low','high']})
# 定义df2
df2 = pd.DataFrame({'alpha':['A','A','B','F'],'pazham':['apple','orange','pine','pear'],
'kilo':['high','low','high','medium'],'price':np.array([5,6,5,7])})
# print(df1)
# print(df2)
# 基于共同列alpha的内连接
df3 = pd.merge(df1,df2,how='inner',on='alpha')
df3
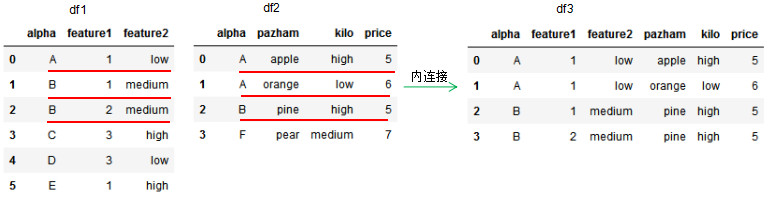
取共同列alpha值的交集进行连接。
1.2 外连接
how='outer',dataframe的链接方式为外连接,我们可以理解基于共同列的并集进行连接,参数on设置连接的共有列名。
# 单列的外连接
# 定义df1
df1 = pd.DataFrame({'alpha':['A','B','B','C','D','E'],'feature1':[1,1,2,3,3,1],
'feature2':['low','medium','medium','high','low','high']})
# 定义df2
df2 = pd.DataFrame({'alpha':['A','A','B','F'],'pazham':['apple','orange','pine','pear'],
'kilo':['high','low','high','medium'],'price':np.array([5,6,5,7])})
# 基于共同列alpha的内连接
df4 = pd.merge(df1,df2,how='outer',on='alpha')
df4
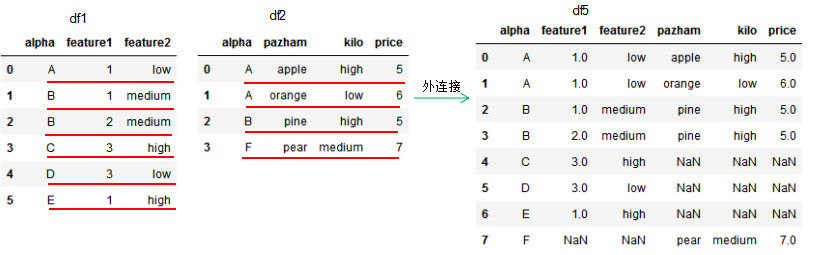
若两个dataframe间除了on设置的连接列外并无相同列,则该列的值置为NaN。
1.3 左连接
how='left',dataframe的链接方式为左连接,我们可以理解基于左边位置dataframe的列进行连接,参数on设置连接的共有列名。
# 单列的左连接
# 定义df1
df1 = pd.DataFrame({'alpha':['A','B','B','C','D','E'],'feature1':[1,1,2,3,3,1],
'feature2':['low','medium','medium','high','low','high']})
# 定义df2
df2 = pd.DataFrame({'alpha':['A','A','B','F'],'pazham':['apple','orange','pine','pear'],
'kilo':['high','low','high','medium'],'price':np.array([5,6,5,7])})
# 基于共同列alpha的左连接
df5 = pd.merge(df1,df2,how='left',on='alpha')
df5
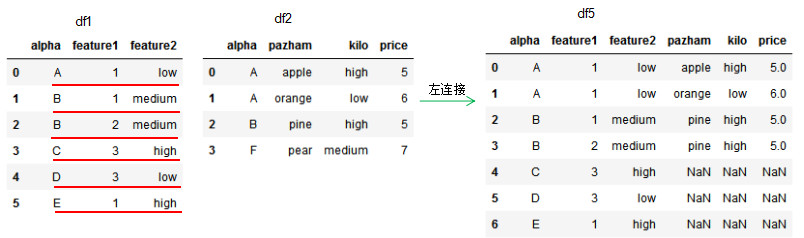
因为df2的连接列alpha有两个'A'值,所以左连接的df5有两个'A'值,若两个dataframe间除了on设置的连接列外并无相同列,则该列的值置为NaN。
1.4 右连接
how='right',dataframe的链接方式为左连接,我们可以理解基于右边位置dataframe的列进行连接,参数on设置连接的共有列名。
# 单列的右连接
# 定义df1
df1 = pd.DataFrame({'alpha':['A','B','B','C','D','E'],'feature1':[1,1,2,3,3,1],
'feature2':['low','medium','medium','high','low','high']})
# 定义df2
df2 = pd.DataFrame({'alpha':['A','A','B','F'],'pazham':['apple','orange','pine','pear'],
'kilo':['high','low','high','medium'],'price':np.array([5,6,5,7])})
# 基于共同列alpha的右连接
df6 = pd.merge(df1,df2,how='right',on='alpha')
df6
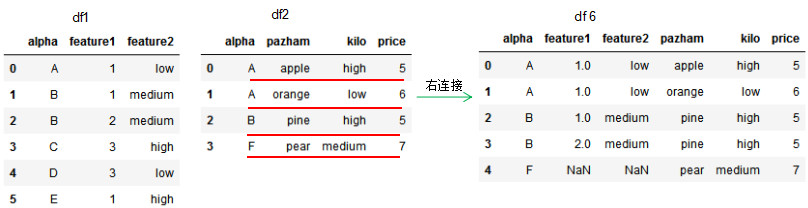
因为df1的连接列alpha有两个'B'值,所以右连接的df6有两个'B'值。若两个dataframe间除了on设置的连接列外并无相同列,则该列的值置为NaN。
1.5 基于多列的连接算法
多列连接的算法与单列连接一致,本节只介绍基于多列的内连接和右连接,读者可自己编码并按照本文给出的图解方式去理解外连接和左连接。
多列的内连接:
# 多列的内连接
# 定义df1
df1 = pd.DataFrame({'alpha':['A','B','B','C','D','E'],'beta':['a','a','b','c','c','e'],
'feature1':[1,1,2,3,3,1],'feature2':['low','medium','medium','high','low','high']})
# 定义df2
df2 = pd.DataFrame({'alpha':['A','A','B','F'],'beta':['d','d','b','f'],'pazham':['apple','orange','pine','pear'],
'kilo':['high','low','high','medium'],'price':np.array([5,6,5,7])})
# 基于共同列alpha和beta的内连接
df7 = pd.merge(df1,df2,on=['alpha','beta'],how='inner')
df7
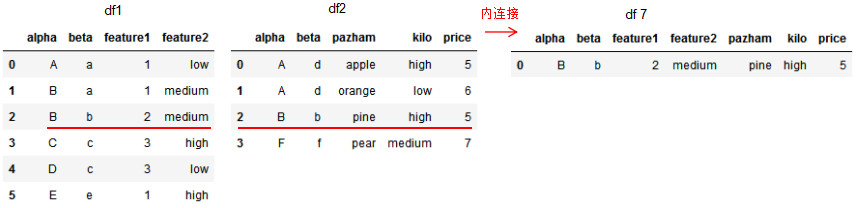
多列的右连接:
# 多列的右连接
# 定义df1
df1 = pd.DataFrame({'alpha':['A','B','B','C','D','E'],'beta':['a','a','b','c','c','e'],
'feature1':[1,1,2,3,3,1],'feature2':['low','medium','medium','high','low','high']})
# 定义df2
df2 = pd.DataFrame({'alpha':['A','A','B','F'],'beta':['d','d','b','f'],'pazham':['apple','orange','pine','pear'],
'kilo':['high','low','high','medium'],'price':np.array([5,6,5,7])})
print(df1)
print(df2)
# 基于共同列alpha和beta的右连接
df8 = pd.merge(df1,df2,on=['alpha','beta'],how='right')
df8
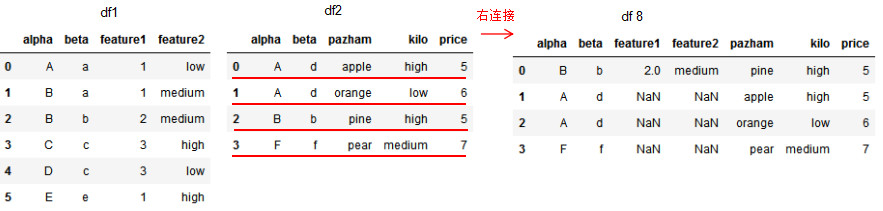
1.6 基于index的连接方法
前面介绍了基于column的连接方法,merge方法亦可基于index连接dataframe。
# 基于column和index的右连接
# 定义df1
df1 = pd.DataFrame({'alpha':['A','B','B','C','D','E'],'beta':['a','a','b','c','c','e'],
'feature1':[1,1,2,3,3,1],'feature2':['low','medium','medium','high','low','high']})
# 定义df2
df2 = pd.DataFrame({'alpha':['A','A','B','F'],'pazham':['apple','orange','pine','pear'],
'kilo':['high','low','high','medium'],'price':np.array([5,6,5,7])},index=['d','d','b','f'])
print(df1)
print(df2)
# 基于df1的beta列和df2的index连接
df9 = pd.merge(df1,df2,how='inner',left_on='beta',right_index=True)
df9
图解index和column的内连接方法:
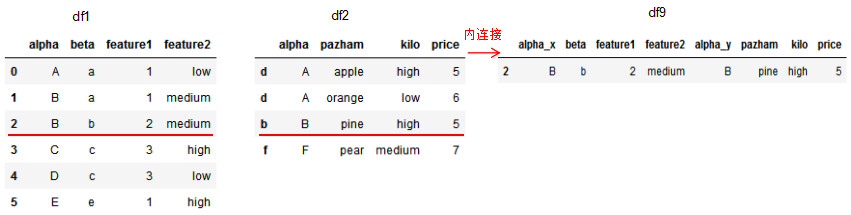
设置参数suffixes以修改除连接列外相同列的后缀名。
# 基于df1的alpha列和df2的index内连接
df9 = pd.merge(df1,df2,how='inner',left_on='beta',right_index=True,suffixes=('_df1','_df2'))
df9

2. join方法
join方法是基于index连接dataframe,merge方法是基于column连接,连接方法有内连接,外连接,左连接和右连接,与merge一致。
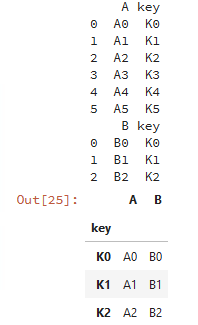
index与index的连接:
caller = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3', 'K4', 'K5'], 'A': ['A0', 'A1', 'A2', 'A3', 'A4', 'A5']})
other = pd.DataFrame({'key': ['K0', 'K1', 'K2'],'B': ['B0', 'B1', 'B2']})
print(caller)print(other)# lsuffix和rsuffix设置连接的后缀名
caller.join(other,lsuffix='_caller', rsuffix='_other',how='inner')

join也可以基于列进行连接:
caller = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3', 'K4', 'K5'], 'A': ['A0', 'A1', 'A2', 'A3', 'A4', 'A5']})
other = pd.DataFrame({'key': ['K0', 'K1', 'K2'],'B': ['B0', 'B1', 'B2']})
print(caller)
print(other)
# 基于key列进行连接
caller.set_index('key').join(other.set_index('key'),how='inner')
因此,join和merge的连接方法类似,这里就不展开join方法了,建议用merge方法。
3. concat方法
concat方法是拼接函数,有行拼接和列拼接,默认是行拼接,拼接方法默认是外拼接(并集),拼接的对象是pandas数据类型。
3.1 series类型的拼接方法
行拼接:
df1 = pd.Series([1.1,2.2,3.3],index=['i1','i2','i3']) df2 = pd.Series([4.4,5.5,6.6],index=['i2','i3','i4']) print(df1) print(df2) # 行拼接 pd.concat([df1,df2])
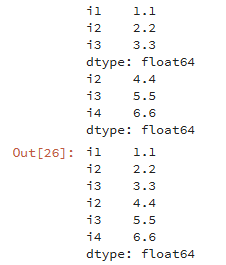
行拼接若有相同的索引,为了区分索引,我们在最外层定义了索引的分组情况。
# 对行拼接分组 pd.concat([df1,df2],keys=['fea1','fea2'])

列拼接:
默认以并集的方式拼接:
# 列拼接,默认是并集 pd.concat([df1,df2],axis=1)

以交集的方式拼接:
# 列拼接的内连接(交) pd.concat([df1,df2],axis=1,join='inner')

设置列拼接的列名:
# 列拼接的内连接(交) pd.concat([df1,df2],axis=1,join='inner',keys=['fea1','fea2'])

对指定的索引拼接:
# 指定索引[i1,i2,i3]的列拼接 pd.concat([df1,df2],axis=1,join_axes=[['i1','i2','i3']])

3.2 dataframe类型的拼接方法
行拼接:
df1 = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3', 'K4', 'K5'], 'A': ['A0', 'A1', 'A2', 'A3', 'A4', 'A5']})
df2 = pd.DataFrame({'key': ['K0', 'K1', 'K2'],'B': ['B0', 'B1', 'B2']})
print(df1)
print(df2)
# 行拼接
pd.concat([df1,df2])

列拼接:
# 列拼接 pd.concat([df1,df2],axis=1)
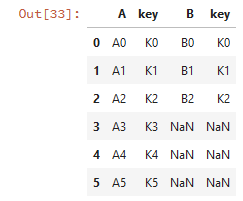
若列拼接或行拼接有重复的列名和行名,则报错:
# 判断是否有重复的列名,若有则报错 pd.concat([df1,df2],axis=1,verify_integrity = True)
ValueError: Indexes have overlapping values: ['key']
4. 小结
merge和join方法基本上能实现相同的功能,建议用merge。
到此这篇关于pandas数据的合并与拼接的实现的文章就介绍到这了,更多相关pandas数据合并与拼接内容请搜索猪先飞以前的文章或继续浏览下面的相关文章希望大家以后多多支持猪先飞!
原文出处:https://mp.weixin.qq.com/s/686SKGkIrlaYdtGfX0uKEQ
相关文章
- 本文给大家分享C#连接SQL数据库和查询数据功能的操作技巧,本文通过图文并茂的形式给大家介绍的非常详细,需要的朋友参考下吧...2021-05-17
- 最基础的对数据的增加删除修改操作实例,菜鸟们收了吧...2013-09-26
- 这篇文章主要介绍了解决Mybatis 大数据量的批量insert问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-01-09
Antd-vue Table组件添加Click事件,实现点击某行数据教程
这篇文章主要介绍了Antd-vue Table组件添加Click事件,实现点击某行数据教程,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-11-17- 这篇文章主要介绍了详解如何清理redis集群的所有数据,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2021-02-18
pandas pd.read_csv()函数中parse_dates()参数的用法说明
这篇文章主要介绍了pandas pd.read_csv()函数中parse_dates()参数的用法说明,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-05- 这篇文章主要介绍了vue 获取到数据但却渲染不到页面上的解决方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-11-19
- 在php中解析xml文档用专门的函数domdocument来处理,把json在php中也有相关的处理函数,我们要把数据xml 数据存到一个数据再用json_encode直接换成json数据就OK了。...2016-11-25
- 这篇文章主要介绍了mybatis-plus 处理大数据插入太慢的解决,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-12-18
- 这篇文章主要介绍了使用list stream:任意对象List拼接字符串操作,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教...2021-09-09
- 这篇文章主要介绍了postgresql数据添加两个字段联合唯一的操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-02-04
- 这篇文章主要介绍了@Cacheable 拼接key的操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-02-13
Vue生命周期activated之返回上一页不重新请求数据操作
这篇文章主要介绍了Vue生命周期activated之返回上一页不重新请求数据操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-07-26- 今天小编就为大家分享一篇Pandas实现DataFrame按行求百分数(比例数),具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-05-09
- 本文主要介绍了python使用pandas按照行数分割表格,文中通过示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下...2021-08-13
- 这篇文章主要介绍了c# socket网络编程,server端接收,client端发送数据,大家参考使用吧...2020-06-25
- 这篇文章主要介绍了解决vue watch数据的方法被调用了两次的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-11-07
- 这篇文章主要介绍了vue 数据(data)赋值问题的解决方案,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-29
- 这篇文章主要介绍了Python3 常用数据标准化方法详解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-24
Vue初始化中的选项合并之initInternalComponent详解
这篇文章主要介绍了Vue初始化中的选项合并之initInternalComponent的相关知识,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2020-06-11