PostgreSQL三种自增列sequence,serial,identity的用法区别
这三个对象都可以实现自增,这里从如下几个维度来看看这几个对象有哪些不同,其中功能性上看,大部分特性都是一致的或者类似的。
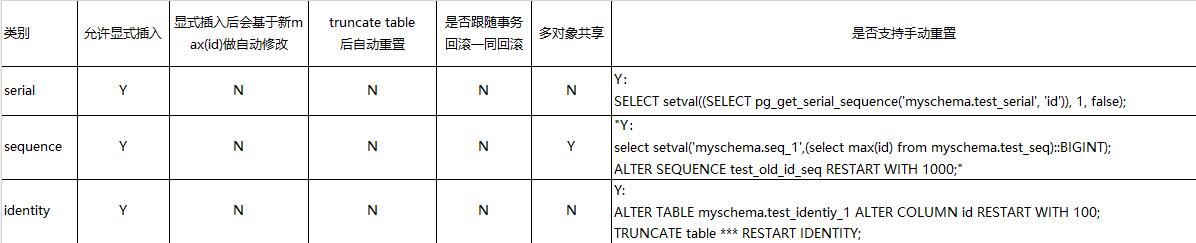
1、sequence在所有数据库中的性质都一样,它是跟具体的字段不是强绑定的,其特点是支持多个对个对象之间共享。
sequence作为自增字段值的时候,对表的写入需要另外单独授权sequence(GRANT USAGE ON SEQUENCE test_old_id_seq;)
sequence类型的字段表,在使用CREATE TABLE new_table LIKE old_table的时候,新表的自增字段会已久指向原始表的sequence
结论:
对于自增字段,无特殊需求的情况下,sequence不适合作为“自增列”,作为最最次选。
2、identity本质是为了兼容标准sql中的语法而新加的,修复了一些serial的缺陷,比如无法通过alter table的方式实现增加或者删除serial字段
2.1 identity定义成generated by default as identity也允许显式插入,
2.2 identity定义成always as identity,加上overriding system value也可以显式不插入
结论:
identity是serial的“增强版”,更适合作为“自增列”使用。
3、sequence,serial,identity共同的缺点是在显式插入之后,无法将自增值更新为表中的最大Id,这一点再显式插入的情况下是潜在自增字段Id冲突的
结论:
自增列在显式插入之后,一定要手动重置为表的最大Id。
4、自增字段的update没有细看,相对来说自增列的显式插入是一种常规操作,那些对自增列的update操作,只要脑子没问题,一般是不会这么干的。
原始手稿,懒得整理了,不涉及原理性的东西,动手试一遍就明白了。
---------------------------------------------------------sequence-------------------------------------------------------------
create sequence myschema.seq_1 INCREMENT BY 1 MINVALUE 1 START WITH 1;
create table myschema.test_seq
(
id int not null default nextval('myschema.seq_1') primary key,
name varchar(10)
);
隐式插入
insert into myschema.test_seq (name) values ('aaa');
insert into myschema.test_seq (name) values ('bbb');
insert into myschema.test_seq (name) values ('ccc');
select * from myschema.test_seq;
显式插入
insert into myschema.test_seq (id,name) values (5,'ddd');
select * from test_seq;
再次隐式插入
--可以正常插入
insert into myschema.test_seq (name) values ('eee');
--插入失败,主键重复,因为序列自身是递增的,不会关心表中被显式插入的数据
insert into myschema.test_seq (name) values ('fff');
--重置序列的最大值
select setval('myschema.seq_1',(select max(id) from myschema.test_seq)::BIGINT);
--事务回滚后,序列号并不会回滚
begin;
insert into myschema.test_seq (name) values ('ggg');
rollback;
-- truncate 表之后,序列不受影响
truncate table myschema.test_seq;
--重置序列
ALTER SEQUENCE myschema.seq_1 RESTART WITH 1;
---------------------------------------------------------serial-------------------------------------------------------------
create table myschema.test_serial
(
id serial primary key,
name varchar(100)
)
select * from test_serial;
insert into myschema.test_serial(name) values ('aaa');
insert into myschema.test_serial(name) values ('bbb');
insert into myschema.test_serial(name) values ('ccc');
select * from myschema.test_serial;
--显式插入,可以执行
insert into myschema.test_serial(id,name) values (5,'ccc');
--再次隐式插入,第二次会报错,因为隐式插入的话,serial会基于显式插入之前的Id做自增,serial无法意识到当前已经存在的最大值
insert into myschema.test_serial(name) values ('xxx');
insert into myschema.test_serial(name) values ('yyy');
select * from myschema.test_serial;
--truncate table 后serial不会重置
truncate table myschema.test_serial;
insert into myschema.test_serial(name) values ('aaa');
insert into myschema.test_serial(name) values ('bbb');
insert into myschema.test_serial(name) values ('ccc');
select * from myschema.test_serial;
--验证是否会随着事务一起回滚,结论:不会
begin;
insert into myschema.test_serial(name) values ('yyy');
rollback;
--重置serial,需要注意的是重置的Id必须要大于相关表的字段最大Id,否则会产生重号
SELECT SETVAL((SELECT pg_get_serial_sequence('myschema.test_serial', 'id')), 1, false);
---------------------------------------------------------identity-------------------------------------------------------------
drop table myschema.test_identiy_1
create table myschema.test_identiy_1
(
id int generated always as identity (cache 100 START WITH 1 INCREMENT BY 1) primary key ,
name varchar(100)
);
create table myschema.test_identiy_2
(
id int generated by default as identity (cache 100 START WITH 1 INCREMENT BY 1) primary key ,
name varchar(100)
);
insert into myschema.test_identiy_1(name) values ('aaa');
insert into myschema.test_identiy_1(name) values ('bbb');
insert into myschema.test_identiy_1(name) values ('ccc');
insert into myschema.test_identiy_2(name) values ('aaa');
insert into myschema.test_identiy_2(name) values ('bbb');
insert into myschema.test_identiy_2(name) values ('ccc');
select * from myschema.test_identiy_1;
--显式插入值,如果定义为generated always as identity则不允许显式插入,除非增加overriding system value 提示
--一旦提示了overriding system value,可以
insert into myschema.test_identiy_1(id,name) values (5,'ccc');
insert into myschema.test_identiy_1(id,name)overriding system value values (5,'ccc');
select * from myschema.test_identiy_2;
--显式插入值,如果定义为generated by default as identity则允许显式插入,
insert into myschema.test_identiy_2(id,name) values (5,'ccc');
--显式插入后,继续隐式插入,第二次插入会报错,identity已久是不识别表中显式插入后的最大值
insert into myschema.test_identiy_2(name) values ('xxx');
insert into myschema.test_identiy_2(name) values ('yyy');
select * from myschema.test_identiy_2;
总之个identity很扯淡,你定义成always as identity,加上overriding system value可以显式不插入
定义成generated by default as identity也允许显式插入
不管怎么样,既然都允许显式插入,那扯什么淡的来个overriding system value
--truncate后再次插入,自增列不会重置
truncate table myschema.test_identiy_1;
select * from myschema.test_identiy_1;
begin;
insert into myschema.test_identiy_1(name) values ('xxx');
rollback;
--truncate并且RESTART IDENTITY后,会重置自增列
TRUNCATE table myschema.test_identiy_1 RESTART IDENTITY;
select * from myschema.test_identiy_1
--identity自增列的重置表或者更改
ALTER TABLE myschema.test_identiy_1 ALTER COLUMN id RESTART WITH 100;
实际中更改identity自增长列的当前起始值(已有的最大值+1):
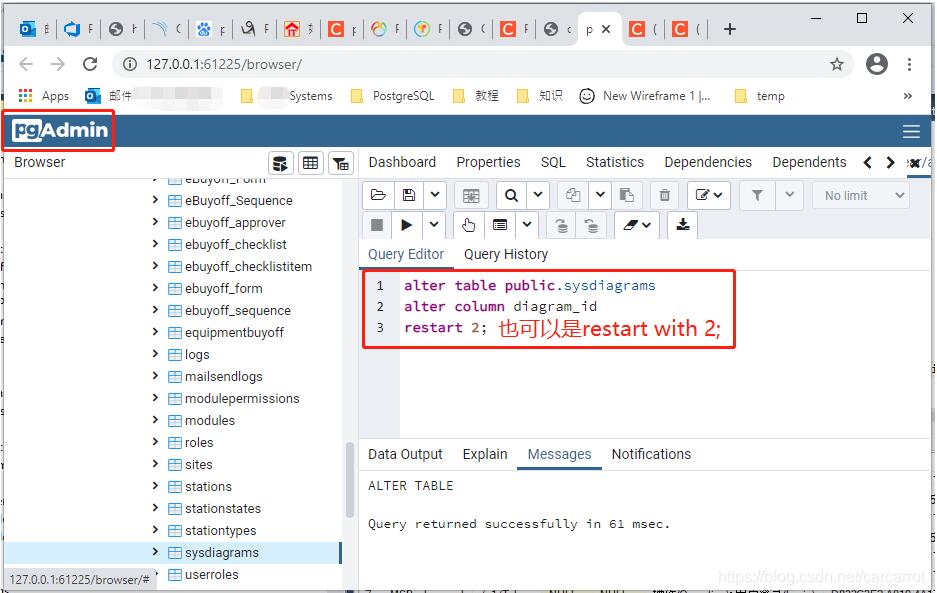
补充:PostgreSQL不同的表使用不同的自增序列
hibernate 配置文件里面应该是这样的:
<id name="id"> <generator class="sequence"> <param name="sequence">adminuser</param> </generator> </id>
使用xdoclet时 类里面的配置应该是这样的:
/** * @hibernate.id generator-class="sequence" * @hibernate.generator-param name="sequence" value="adminuser" */ private int id;
以上为个人经验,希望能给大家一个参考,也希望大家多多支持猪先飞。如有错误或未考虑完全的地方,望不吝赐教。
相关文章
- 这篇文章主要介绍了PostgreSQL判断字符串是否包含目标字符串的多种方法,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-02-23
- 这篇文章主要介绍了PostgreSQL TIMESTAMP类型 时间戳操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-12-26
- 这篇文章主要介绍了postgresql 实现多表关联删除操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-01-02
- 这篇文章主要介绍了Postgresl 如何选择正确的关闭模式,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-01-18
- 这篇文章主要介绍了postgresql数据添加两个字段联合唯一的操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-02-04
- 这篇文章主要介绍了PostgreSQL 字符串处理与日期处理操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-02-01
- 这篇文章主要介绍了postgresql重置序列起始值,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-01-04
- 这篇文章主要介绍了postgresql 中的时间处理小技巧(推荐),本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-03-29
- 通过合理的设计,可以将选择一定的规则,将大表切分多个不重不漏的子表,这就是传说中的partitioning。比如,我们可以按时间切分,每天一张子表,比如我们可以按照某其他字段分割,总之了就是化整为零,提高查询的效能...2020-07-11
- 这篇文章主要介绍了基于postgresql数据库锁表问题的解决,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-12-30
- 这篇文章主要介绍了基于PostgreSQL和mysql数据类型对比兼容,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-12-25
- 这篇文章主要介绍了PostgreSQL 中的单引号与双引号用法说明,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-02-01
- 这篇文章主要介绍了postgresql 利用xlog进行热备操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-01-16
- 这篇文章主要介绍了Postgresql数据库之创建和修改序列的操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-02-04
- 这篇文章主要介绍了Postgresql中xlog生成和清理逻辑操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-01-16
- 这篇文章主要介绍了postgresql影子用户实践场景分析,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-03-06
- 这篇文章主要介绍了PostgreSQL 恢复误删数据的操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-01-18
- 这篇文章主要介绍了解决postgresql 自增id作为key重复的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-02-04
- 这篇文章主要介绍了PostgreSQL 实现定时job执行(pgAgent),具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-01-16
- 这篇文章主要介绍了postgresql的jsonb数据查询和修改的方法,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-03-03