php curl主动推送最新内容给百度收录
百度链接提交三种方式:
1、主动推送:最为快速的提交方式,推荐您将站点当天新产出链接立即通过此方式推送给百度,以保证新链接可以及时被百度收录。
2、sitemap:您可以定期将网站链接放到sitemap中,然后将sitemap提交给百度。百度会周期性的抓取检查您提交的sitemap,对其中的链接进行处理,但收录速度慢于主动推送。
3、手工提交:一次性提交链接给百度,可以使用此种方式。
下面介绍使用curl主动推送链接的方式PHP示例,使用curl扩展:
$urls = array(
'http://www.example.com/1.html',
'http://www.example.com/2.html',
);
$api = 'http://data.zz.baidu.com/urls?site=www.dayecn.com&token=Db0ZoYUOwUyEp87Z';
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => implode("\n", $urls),
CURLOPT_HTTPHEADER => array('Content-Type: text/plain'),
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
echo $result;
首先要在百度站长平台验证站点,然后获取token密钥,才有权限推送url给百度。百度站长平台:http://zhanzhang.baidu.com
可以在发布一篇文章的时候就把这篇文章的url推送给百度站长平台,或者批量推送,通过返回的$result状态判断推送是否成功,返回的状态码说明:
推送成功
状态码为200,可能返回以下字段:
字段 是否必选 参数类型 说明
success 是 int 成功推送的url条数
remain 是 int 当天剩余的可推送url条数
not_same_site 否 array 由于不是本站url而未处理的url列表
not_valid 否 array 不合法的url列表
成功返回示例:
{
"remain":4999998,
"success":2,
"not_same_site":[],
"not_valid":[]
}
推送失败
状态码为4xx,返回字段有:
字段 是否必传 类型 说明
error 是 int 错误码,与状态码相同
message 是 string 错误描述
失败返回示例:
{
"error":401,
"message":"token is not valid"
}
数据源架构模式 - 表入口模式
表入口模式充当数据库表访问入口的对象,一个实例处理表中的所有行。
可以理解为对之前分散在各个页面的sql语句进行封装,一张表就是一个对象,该对象处理所有与该表有关的业务逻辑,很好的提高了代码的复用性。
现在想起来,当初刚毕业那会儿,经常使用表入口模式。
具体的实现方式参见代码:
database.php
<?php
class Database{
//只是为了演示,通常情况下数据库的配置是会单独写在配置文件中的
private static $_dbConfig = array(
'host' => '127.0.0.1',
'username' => 'root',
'pwd' => '',
'dbname' => 'bussiness'
);
private static $_instance;
public static function getInstance(){
if(is_null(self::$_instance)){
self::$_instance = new mysqli(self::$_dbConfig['host'], self::$_dbConfig['username'], self::$_dbConfig['pwd'], self::$_dbConfig['dbname']);
if(self::$_instance->connect_errno){
throw new Exception(self::$_instance->connect_error);
}
}
return self::$_instance;
}
}
person.php
<?php
require_once 'database.php';
class Person extends Database{
public $instance;
public $table = 'person';
public function __construct(){
$this->instance = Person::getInstance();
}
public function getPersonById($personId){
$sql = "select * from $this->table where id=$personId";
echo $sql;
return $this->instance->query($sql);
}
/**其他的一些增删改查操作方法...**/
}
index.php
<?php require_once 'person.php'; $person = new Person(); var_dump($person->getPersonById(1)->fetch_assoc()); die();
运行结果:
select * from person where id=1
array (size=2)
'id' => string '1' (length=1)
'name' => string 'ben' (length=3)
数据源架构模式 - 行入口模式
一、概念
行数据入口(Row Data Gateway):充当数据源中单条记录入口的对象,每行一个实例。
二、简单实现行数据入口
为了方便理解,还是先简单实现:
<?php
/**
* 企业应用架构 数据源架构模式之行数据入口 2010-09-27 sz
* @author phppan.p#gmail.com http://www.phppan.com
* 哥学社成员(http://www.blog-brother.com/)
* @package architecture
*/
class PersonGateway {
private $_name;
private $_id;
private $_birthday;
public function __construct($id, $name, $birthday) {
$this->setId($id);
$this->setName($name);
$this->setBirthday($birthday);
}
public function getName() {
return $this->_name;
}
public function setName($name) {
$this->_name = $name;
}
public function getId() {
return $this->_id;
}
public function setId($id) {
$this->_id = $id;
}
public function getBirthday() {
return $this->_birthday;
}
public function setBirthday($birthday) {
$this->_birthday = $birthday;
}
/**
* 入口类自身拥有更新操作
*/
public function update() {
$data = array('id' => $this->_id, 'name' => $this->_name, 'birthday' => $this->_birthday);
$sql = "UPDATE person SET ";
foreach ($data as $field => $value) {
$sql .= "`" . $field . "` = '" . $value . "',";
}
$sql = substr($sql, 0, -1);
$sql .= " WHERE id = " . $this->_id;
return DB::query($sql);
}
/**
* 入口类自身拥有插入操作
*/
public function insert() {
$data = array('name' => $this->_name, 'birthday' => $this->_birthday);
$sql = "INSERT INTO person ";
$sql .= "(`" . implode("`,`", array_keys($data)) . "`)";
$sql .= " VALUES('" . implode("','", array_values($data)) . "')";
return DB::query($sql);
}
public static function load($rs) {
/* 此处可加上缓存 */
return new PersonGateway($rs['id'] ? $rs['id'] : NULL, $rs['name'], $rs['birthday']);
}
}
/**
* 人员查找类
*/
class PersonFinder {
public function find($id) {
$sql = "SELECT * FROM person WHERE id = " . $id;
$rs = DB::query($sql);
return PersonGateway::load($rs);
}
public function findAll() {
$sql = "SELECT * FROM person";
$rs = DB::query($sql);
$result = array();
if (is_array($rs)) {
foreach ($rs as $row) {
$result[] = PersonGateway::load($row);
}
}
return $result;
}
}
class DB {
/**
* 这只是一个执行SQL的演示方法
* @param string $sql 需要执行的SQL
*/
public static function query($sql) {
echo "执行SQL: ", $sql, " <br />";
if (strpos($sql, 'SELECT') !== FALSE) { // 示例,对于select查询返回查询结果
return array('id' => 1, 'name' => 'Martin', 'birthday' => '2010-09-15');
}
}
}
/**
* 客户端调用
*/
class Client {
/**
* Main program.
*/
public static function main() {
header("Content-type:text/html; charset=utf-8");
/* 写入示例 */
$data = array('name' => 'Martin', 'birthday' => '2010-09-15');
$person = PersonGateway::load($data);
$person->insert();
/* 更新示例 */
$data = array('id' => 1, 'name' => 'Martin', 'birthday' => '2010-09-15');
$person = PersonGateway::load($data);
$person->setName('Phppan');
$person->update();
/* 查询示例 */
$finder = new PersonFinder();
$person = $finder->find(1);
echo $person->getName();
}
}
Client::main();
?>三、运行机制
●行数据入口是单条记录极其相似的对象,在该对象中数据库中的每一列为一个域。
●行数据入口一般能实现从数据源类型到内存中类型的任意转换。
●行数据入口不存在任何领域逻辑,如果存在,则是活动记录。
●在实例可看到,为了从数据库中读取信息,设置独立的OrderFinder类。当然这里也可以选择不新建类,采用静态查找方法,但是它不支持需要为不同数据源提供不同查找方法的多态。因此这里最好单独设置查找方法的对象。
●行数据入口除了可以用于表外还可以用于视图。需要注意的是视图的更新操作。
●在代码中可见“定义元数据映射”,这是一种很好的作法,这样一来,所有的数据库访问代码都可以在自动建立过程中自动生成。
四、使用场景
4.1 事务脚本
可以很好地分离数据库访问代码,并且也很容易被不同的事务脚本重用。不过可能会发现业务逻辑在多处脚本中重复出现,这些逻辑可能在行数据入口中有用。不断移动这些逻辑会使行数据入口演变为活动记录,这样减少了业务逻辑的重复。
4.2 领域模型
如果要改变数据库的结构但不想改变领域逻辑,采用行数据入口是不错的选择。大多数情况,数据映射器更加适合领域模型。
行数据入口能和数据映射器一起配合使用,尽管这样看起来有点多此一举,不过,当行数据入口从元数据自动生成,而数据映射器由手动实现时,这种方法会很有效。
数据源架构模式 - 活动记录
【活动记录的意图】
一个对象,它包装数据表或视图中某一行,封装数据库访问,并在这些数据上增加了领域逻辑。
【活动记录的适用场景】
适用于不太复杂的领域逻辑,如CRUD操作等。
【活动记录的运行机制】
对象既有数据又有行为。其使用最直接的方法,将数据访问逻辑置于领域对象中。
活动记录的本质是一个领域模型,这个领域模型中的类和基数据库中的记录结构应该完全匹配,类的每个域对应表的每一列。
一般来说,活动记录包括如下一些方法:
1、由数据行构造一个活动记录实例;
2、为将来对表的插入构造一个新的实例;
3、用静态查找方法来包装常用的SQL查询和返回活动记录;
4、更新数据库并将活动记录中的数据插入数据库;
5、获取或设置域;
6、实现部分业务逻辑。
【活动记录的优点和缺点】
优点:
1、简单,容易创建并且容易理解。
2、在使用事务脚本时,减少代码复制。
3、可以在改变数据库结构时不改变领域逻辑。
4、基于单个活动记录的派生和测试验证会很有效。
缺点:
1、没有隐藏关系数据库的存在。
2、仅当活动记录对象和数据库中表直接对应时,活动记录才会有效。
3、要求对象的设计和数据库的设计紧耦合,这使得项目中的进一步重构很困难
【活动记录与其它模式】
数据源架构模式之行数据入口:活动记录与行数据入口十分类似。二者的主要差别是行数据入口 仅有数据库访问而活动记录既有数据源逻辑又有领域逻辑。
【活动记录的PHP示例】
<?php
/**
* 企业应用架构 数据源架构模式之活动记录 2010-10-17 sz
* @author phppan.p#gmail.com http://www.phppan.com
* 哥学社成员(http://www.blog-brother.com/)
* @package architecture
*/
/**
* 定单类
*/
class Order {
/**
* 定单ID
* @var <type>
*/
private $_order_id;
/**
* 客户ID
* @var <type>
*/
private $_customer_id;
/**
* 定单金额
* @var <type>
*/
private $_amount;
public function __construct($order_id, $customer_id, $amount) {
$this->_order_id = $order_id;
$this->_customer_id = $customer_id;
$this->_amount = $amount;
}
/**
* 实例的删除操作
*/
public function delete() {
$sql = "DELETE FROM Order SET WHERE order_id = " . $this->_order_id . " AND customer_id = " . $this->_customer_id;
return DB::query($sql);
}
/**
* 实例的更新操作
*/
public function update() {
}
/**
* 插入操作
*/
public function insert() {
}
public static function load($rs) {
return new Order($rs['order_id'] ? $rs['order_id'] : NULL, $rs['customer_id'], $rs['amount'] ? $rs['amount'] : 0);
}
}
class Customer {
private $_name;
private $_customer_id;
public function __construct($customer_id, $name) {
$this->_customer_id = $customer_id;
$this->_name = $name;
}
/**
* 用户删除定单操作 此实例方法包含了业务逻辑
* 通过调用定单实例实现
* 假设此处是对应的删除操作(实际中可能是一种以某字段来标记的假删除操作)
*/
public function deleteOrder($order_id) {
$order = Order::load(array('order_id' => $order_id, 'customer_id' => $this->_customer_id));
return $order->delete();
}
/**
* 实例的更新操作
*/
public function update() {
}
/**
* 入口类自身拥有插入操作
*/
public function insert() {
}
public static function load($rs) {
/* 此处可加上缓存 */
return new Customer($rs['customer_id'] ? $rs['customer_id'] : NULL, $rs['name']);
}
/**
* 根据客户ID 查找
* @param integer $id 客户ID
* @return Customer 客户对象
*/
public static function find($id) {
return CustomerFinder::find($id);
}
}
/**
* 人员查找类
*/
class CustomerFinder {
public static function find($id) {
$sql = "SELECT * FROM person WHERE customer_id = " . $id;
$rs = DB::query($sql);
return Customer::load($rs);
}
}
class DB {
/**
* 这只是一个执行SQL的演示方法
* @param string $sql 需要执行的SQL
*/
public static function query($sql) {
echo "执行SQL: ", $sql, " <br />";
if (strpos($sql, 'SELECT') !== FALSE) { // 示例,对于select查询返回查询结果
return array('customer_id' => 1, 'name' => 'Martin');
}
}
}
/**
* 客户端调用
*/
class Client {
/**
* Main program.
*/
public static function main() {
header("Content-type:text/html; charset=utf-8");
/* 加载客户ID为1的客户信息 */
$customer = Customer::find(1);
/* 假设用户拥有的定单id为 9527*/
$customer->deleteOrder(9527);
}
}
Client::main();
?>
同前面的文章一样,这仅仅是一个活动记录的示例,关于活动记录模式的应用,可以查看Yii框架中的DB类,在其源码中有一个CActiveRecord抽象类,从这里可以看到活动记录模式的应用
另外,如果从事务脚本中创建活动记录,一般是首先将表包装为入口,接着开始行为迁移,使表深化成为活动记录。
对于活动记录中的域的访问和设置可以如yii框架一样,使用魔术方法__set方法和__get方法。
数据源架构模式 - 数据映射器
一:数据映射器
关系型数据库用来存储数据和关系,对象则可以处理业务逻辑,所以,要把数据本身和业务逻辑糅杂到一个对象中,我们要么使用 活动记录,要么把两者分开,通过数据映射器把两者关联起来。
数据映射器是分离内存对象和数据库的中间软件层,下面这个时序图描述了这个中间软件层的概念:
在这个时序图中,我们还看到一个概念,映射器需能够获取领域对象(在这个例子中,a Person 就是一个领域对象)。而对于数据的变化(或者说领域对象的变化),映射器还必须要知道这些变化,在这个时候,我们就需要 工作单元 模式(后议)。
从上图中,我们仿佛看到 数据映射器 还蛮简单的,复杂的部分是:我们需要处理联表查询,领域对象的继承等。领域对象的字段则可能来自于数据库中的多个表,这种时候,我们就必须要让数据映射器做更多的事情。是的,以上我们说到了,数据映射器要能做到两个复杂的部分:
1:感知变化;
2:通过联表查询的结果,为领域对象赋值;
为了感知变化以及与数据库对象保持一致,则需要 标识映射(架构模式对象与关系结构模式之:标识域(Identity Field)),这通常需要有 标识映射的注册表,或者为每个查找方法持有一个 标识映射,下面的代码是后者:
void Main()
{
SqlHelper.ConnectionString = "Data Source=xxx;Initial Catalog=xxx;Integrated Security=False;User ID=sa;Password=xxx;Connect Timeout=15;Encrypt=False;TrustServerCertificate=False";
var user1 = User.FindUser("6f7ff44435f3412cada61898bcf0df6c");
var user2 = User.FindUser("6f7ff44435f3412cada61898bcf0df6c");
(user1 == user2).Dump();
"END".Dump();
}
public abstract class BaseMode
{
public string Id {get; set;}
public string Name {get; set;}
}
public class User : BaseMode
{
static UserMap map = new UserMap();
public static User FindUser(string id)
{
var user = map.Find(id);
return user;
}
}
public class UserMap : AbstractMapper<User>
{
public User Find(string id)
{
return (User)AbstractFind(id);
}
protected override User AbstractFind(string id)
{
var user = base.AbstractFind(id);
if( user == null )
{
"is Null".Dump();
string sql = "SELECT * FROM [EL_Organization].[User] WHERE ID=@Id";
var pms = new SqlParameter[]
{
new SqlParameter("@Id", id)
};
var ds = SqlHelper.ExecuteDataset(CommandType.Text, sql, pms);
user = DataTableHelper.ToList<User>(ds.Tables[0]).FirstOrDefault();
if(user == null)
{
return null;
}
user = Load(user);
return user;
}
return user;
}
public List<User> FindList(string name)
{
// SELECT * FROM USER WHERE NAME LIKE NAME
List<User> users = null;
return LoadAll(users);
}
public void Update(User user)
{
// UPDATE USER SET ....
}
}
public abstract class AbstractMapper<T> where T : BaseMode
{
// 这里的问题是,随着对象消失,loadedMap就被回收
protected Dictionary<string, T> loadedMap = new Dictionary<string, T>();
protected T Load(T t)
{
if(loadedMap.ContainsKey(t.Id) )
{
return loadedMap[t.Id];
}
else
{
loadedMap.Add(t.Id, t);
return t;
}
}
protected List<T> LoadAll(List<T> ts)
{
for(int i=0; i < ts.Count; i++)
{
ts[i] = Load(ts[i]);
}
return ts;
}
protected virtual T AbstractFind(string id)
{
if(loadedMap.ContainsKey(id))
{
return loadedMap[id];
}
else
{
return null;
}
}
}
上面是一个简单的映射器,它具备了 标识映射 功能。由于有标识映射,所以我们运行这段代码得到的结果是: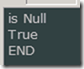
回归本问实质,问题:什么叫 “数据映射”
其实,这个问题很关键,
UserMap 通过 Find 方法,将数据库记录变成了一个 User 对象,这就叫 “数据映射”,但是,真正起到核心作用的是 user = DataTableHelper.ToList<User>(ds.Tables[0]).FirstOrDefault(); 这行代码。更进一步的,DataTableHelper.ToList<T> 这个方法完成了 数据映射 功能。
那么,DataTableHelper.ToList<T> 方法具体干了什么事情,实际上,无非就是根据属性名去获取 DataTable 的字段值。这是一种简便的方法,或者说,在很多业务不复杂的场景下,这也许是个好办法,但是,因为业务往往是复杂的,所以实际情况下,我们使用这个方法的情况并不是很多,大多数情况下,我们需要像这样编码来完成映射:
someone.Name = Convert.ToString(row["Name"])
不要怀疑,上面这行代码,就叫数据映射,任何高大上的概念,实际上就是那条你写了很多遍的代码。
1.1 EntityFramework 中的数据映射
这是一个典型的 EF 的数据映射类,
public class CourseMap : EntityTypeConfiguration<Course>
{
public CourseMap()
{
// Primary Key
this.HasKey(t => t.CourseID);
// Properties
this.Property(t => t.CourseID)
.HasDatabaseGeneratedOption(DatabaseGeneratedOption.None);
this.Property(t => t.Title)
.IsRequired()
.HasMaxLength(100);
// Table & Column Mappings
this.ToTable("Course");
this.Property(t => t.CourseID).HasColumnName("CourseID");
this.Property(t => t.Title).HasColumnName("Title");
this.Property(t => t.Credits).HasColumnName("Credits");
this.Property(t => t.DepartmentID).HasColumnName("DepartmentID");
// Relationships
this.HasMany(t => t.People)
.WithMany(t => t.Courses)
.Map(m =>
{
m.ToTable("CourseInstructor");
m.MapLeftKey("CourseID");
m.MapRightKey("PersonID");
});
this.HasRequired(t => t.Department)
.WithMany(t => t.Courses)
.HasForeignKey(d => d.DepartmentID);
}
}
我们可以看到,EF 的数据映射,那算是真正的数据映射。最基本的,其在内部无非是干了一件这样的事情:
数据库是哪个字段,对应的内存对象的属性是哪个属性。
最终,它都是通过一个对象工厂把领域模型生成出来,其原理大致如下:
internal static Course BuildCourse(IDataReader reader)
{
Course course = new Course(reader[FieldNames.CourseId]);
contract.Title = reader[FieldNames.Title].ToString();
…
return contract;
}
二:仓储库
UserMap 关于 数据映射器 的概念是不是觉得太重了?因为它干了 映射 和 持久化 的事情,它甚至还得持有 工作单元。那么,如果我们能不能像 EF 一样,映射器 只干映射的事情,而把其余事情分出去呢?可以,分离出去的这部分就叫做 仓储库。
三:再多说一点 DataTableHelper.ToList<T>,简化的数据映射器
其实就是 DataTable To List 了。如果你在用 EF 或者 NHibernate 这样的框架,那么,就用它们提供的映射器好了(严格来说,你不是在使用它们的映射器。因为这些框架本身才是在使用自己的映射器,我们只是在配置映射器所要的数据和关系而已,有时候,这些配置是在配置文件中,有时候是在字段或属性上加 Attribute,有时候则是简单但庞大的单行代码)。我们当然也可以创建自己的 标准的 映射器,Tim McCarthy 在 《领域驱动设计 C# 2008 实现》 中就实现了这样的映射器。但是,EF 和 NHibernate 固然很好,但是很多时候我们还是不得不使用 手写SQL,因为:
1:EF 和 NHibernate 是需要学习成本的,这代表者团队培训成本高,且易出错的;
2:不应放弃 手写SQL 的高效性。
php语言本身不支持多线程,所以开发爬虫程序效率并不高,借助Curl Multi 它可以实现并发多线程的访问多个url地址。用 Curl Multi 多线程下载文件代码:
代码1:将获得的代码直接写入某个文件
<?php
$urls =array(
'http://www.111cn.net/',
'http://www.baidu.com/',
);// 设置要抓取的页面URL
$save_to='test.txt'; // 把抓取的代码写入该文件
$st =fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i =>$url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT,"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st);// 设置将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
}// 初始化
do {
curl_multi_exec($mh,$active);
}while ($active); // 执行
foreach ($urls as $i =>$url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}// 结束清理
curl_multi_close($mh);
fclose($st);
?>
代码2:将获得的代码先放入变量,再写入某个文件
<?php
$urls =array(
'http://m.111cn.net/',
'http://www.111cn.net/',
'http://www.163.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st =fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i =>$url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT,"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 设置不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
}while ($active);
foreach ($urls as $i =>$url) {
$data = curl_multi_getcontent($conn[$i]);// 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件。当然,也可以不写入文件,比如存入数据库
}// 获得数据变量,并写入文件
foreach ($urls as $i =>$url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
?>
curl抓取网页中文乱码的解决方法
function ppost($url,$data,$ref){ // 模拟提交数据函数
$curl = curl_init(); // 启动一个CURL会话
curl_setopt($curl, CURLOPT_URL, $url); // 要访问的地址
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, 0); // 对认证证书来源的检查
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, 1); // 从证书中检查SSL加密算法是否存在
curl_setopt($curl, CURLOPT_USERAGENT, $_SERVER['HTTP_USER_AGENT']); // 模拟用户使用的浏览器
curl_setopt($curl, CURLOPT_FOLLOWLOCATION, 1); // 使用自动跳转
curl_setopt($curl, CURLOPT_REFERER, $ref);
curl_setopt($curl, CURLOPT_POST, 1); // 发送一个常规的Post请求
curl_setopt($curl, CURLOPT_POSTFIELDS, $data); // Post提交的数据包
curl_setopt($curl, CURLOPT_COOKIEFILE,$GLOBALS ['cookie_file']); // 读取上面所储存的Cookie信息
curl_setopt($curl, CURLOPT_COOKIEJAR, $GLOBALS['cookie_file']); // 存放Cookie信息的文件名称
curl_setopt($curl, CURLOPT_HTTPHEADER,array('Accept-Encoding: gzip, deflate'));
curl_setopt($curl, CURLOPT_ENCODING, 'gzip,deflate');这个是解释gzip内容.................
curl_setopt($curl, CURLOPT_TIMEOUT, 30); // 设置超时限制防止死循环
curl_setopt($curl, CURLOPT_HEADER, 0); // 显示返回的Header区域内容
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1); // 获取的信息以文件流的形式返回
$tmpInfo = curl_exec($curl); // 执行操作
if (curl_errno($curl)) {
echo 'Errno'.curl_error($curl);
}
curl_close($curl); // 关键CURL会话
return $tmpInfo; // 返回数据
}
按地区搜索:
http://api.map.baidu.com/geosearch/v3/local?region=%E5%8E%A6%E9%97%A8&ak=pWiNP7mGeptewlpldEdv3Ur3&geotable_id=*****
按位置中心点搜索(距离中心位置1800米):
http://api.map.baidu.com/geosearch/v3/nearby?ak=pWiNP7mGeptewlpldEdv3Ur3&geotable_id=***&location=118.145572,24.49264&radius=1800
程序代码如下
首先要把数据录入到百度云数据库
用接口提交位置信息,坐标经纬度到百度lbs云数据库。
百度提供可视化的LBS云数据库管理:
http://lbsyun.baidu.com/datamanager/datamanage
已下是我写的一个提交数据接口:
这里是提交或更新一个lbs数据。
function ptolbs($data,$lbsid){
if($lbsid<=0){
$purl = 'http://api.map.baidu.com/geodata/v3/poi/create';
}else{
$data['id']=$lbsid;
$purl = "http://api.map.baidu.com/geodata/v3/poi/update";
}
$data['ak']="pWiNP7mGeptewlpldEdv3Ur3";
$data['geotable_id']="***";//你的数据库ID
$data['coord_type']="3";
$re = curlpost($purl,$data);
$re = json_decode($re,true);
if($re["status"]==0){
$lbsid =$re['id'];
}else{
$lbsid = -1;
}
return $lbsid;
}
function curlpost($c_url,$data)
{
$curl = curl_init(); // 启动一个CURL会话
curl_setopt($curl, CURLOPT_URL, $c_url); // 要访问的地址
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, 0); // 对认证证书来源的检查
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, 1); // 从证书中检查SSL加密算法是否存在
curl_setopt($curl, CURLOPT_USERAGENT, $_SERVER['HTTP_USER_AGENT']); // 模拟用户使用的浏览器
// curl_setopt($curl, CURLOPT_FOLLOWLOCATION, 1); // 使用自动跳转
curl_setopt($curl, CURLOPT_AUTOREFERER, 1); // 自动设置Referer
curl_setopt($curl, CURLOPT_POST, 1); // 发送一个常规的Post请求
curl_setopt($curl, CURLOPT_POSTFIELDS, $data); // Post提交的数据包
curl_setopt($curl, CURLOPT_TIMEOUT, 30); // 设置超时限制防止死循环
curl_setopt($curl, CURLOPT_HEADER, 0); // 显示返回的Header区域内容
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1); // 获取的信息以文件流的形式返回
$tmpInfo = curl_exec($curl); // 执行操作
if (curl_errno($curl)) {
echo 'Errno'.curl_error($curl);//捕抓异常
}
curl_close($curl); // 关闭CURL会话
return $tmpInfo; // 返回数据
}
原理很简单就是通过我们申请的key 带在curl中post给百度api,然后百度返回查询对应的坐标与数据给我们。
CORS实现POST方式跨域请求数据以前利用iframe时有用到过了,这里再整一个例子供各位参考,此例子是用于js的ajax中哦。
CORS全名Cross-Origin Resource Sharing,顾名思义:跨域分享资源,这是W3C制定的跨站资源分享标准。
目前包括IE10+、chrome、safari、FF都提供了XMLHttpRequest对象对该标准的支持,在更老的IE8中则提供了xDomainRequest对象,部分实现了该标准;
下面是创建request对象的代码:
var url = "http://www.111cn.net /1.php";
if (XMLHttpRequest) {
var req = new XMLHttpRequest();
// 利用withCredentials属性来判断是否支持跨域请求
if (!("withCredentials" in req)) { // w3c先行
if (window.XDomainRequest) {
req = new XDomainRequest();
}
}
req.open('POST', url, true);
req.onload = function (data) {
alert(this.responseText);
};
req.send();
}
注意xDomainRequest对象只支持http和https协议
在利用XMLHttpRequest对象发POST请求前会发一个options嗅探来确定是否有跨域请求的权限;同时在header头上带上Origin信息来指示来源网站信息,服务器响应时需要带上Access-Control-Allow-Origin头的值是否和Origin信息相匹配。
header("Access-Control-Allow-Origin: http://localhost"); // *为全部域名
CORS的缺点是你必须能控制服务器端的权限,允许你跨域访问
设置CORS实现跨域请求
一、使用php代码实现
#
# CORS config for php
# Code by anrip[mail@anrip.com]
#
function make_cors($origin = '*') {
$request_method = $_SERVER['REQUEST_METHOD'];
if ($request_method === 'OPTIONS') {
header('Access-Control-Allow-Origin:'.$origin);
header('Access-Control-Allow-Credentials:true');
header('Access-Control-Allow-Methods:GET, POST, OPTIONS');
header('Access-Control-Max-Age:1728000');
header('Content-Type:text/plain charset=UTF-8');
header('Content-Length: 0',true);
header('status: 204');
header('HTTP/1.0 204 No Content');
}
if ($request_method === 'POST') {
header('Access-Control-Allow-Origin:'.$origin);
header('Access-Control-Allow-Credentials:true');
header('Access-Control-Allow-Methods:GET, POST, OPTIONS');
}
if ($request_method === 'GET') {
header('Access-Control-Allow-Origin:'.$origin);
header('Access-Control-Allow-Credentials:true');
header('Access-Control-Allow-Methods:GET, POST, OPTIONS');
}
}
二、使用nginx配置实现
# CORS config for nginx
# Code by anrip[mail@anrip.com]
#
location / {
set $origin '*';
if ($request_method = 'OPTIONS') {
add_header 'Access-Control-Allow-Origin' $origin;
#
# Om nom nom cookies
#
add_header 'Access-Control-Allow-Credentials' 'true';
add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS';
#
# Custom headers and headers various browsers *should* be OK with but aren't
#
add_header 'Access-Control-Allow-Headers' 'DNT,X-Mx-ReqToken,Keep-Alive,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type';
#
# Tell client that this pre-flight info is valid for 20 days
#
add_header 'Access-Control-Max-Age' 1728000;
add_header 'Content-Type' 'text/plain charset=UTF-8';
add_header 'Content-Length' 0;
return 204;
}
if ($request_method = 'POST') {
add_header 'Access-Control-Allow-Origin' $origin;
add_header 'Access-Control-Allow-Credentials' 'true';
add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS';
add_header 'Access-Control-Allow-Headers' 'DNT,X-Mx-ReqToken,Keep-Alive,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type';
}
if ($request_method = 'GET') {
add_header 'Access-Control-Allow-Origin' $origin;
add_header 'Access-Control-Allow-Credentials' 'true';
add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS';
add_header 'Access-Control-Allow-Headers' 'DNT,X-Mx-ReqToken,Keep-Alive,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type';
}
}
相关文章
- 专做了百度和google的网盟推广以作推广效果的评估比较。百度的周期为6天,google为4天。 从百度的统计数据可以看出这六天的点击次数总共为464,平均点击花费了0.30元...2017-07-06
如何根据百度地图计算出两地之间的驾驶距离(两种语言js和C#)
以下是使用js代码实现百度地图计算两地距离,代码如下所示:<script src="js/jquery-1.9.0.js" type="text/javascript" language="javascript"></script><script language="javascript" type="text/javascript" src="js/...2015-10-30- 百度联盟封号对于许多的站长来说肯定是会影响到心情的,那么既然是百度联盟封号了我们就肯定有一些原因的,虽然不是你自己搞的或一些其它因素都有可能,我们下面整理一下百...2016-10-10
基于JavaScript实现高德地图和百度地图提取行政区边界经纬度坐标
本文给大家介绍javascript实现高德地图和百度地图提取行政区边界经纬度坐标的相关知识,本文实用性非常高,代码简单易懂,需要的朋友参考下吧...2016-01-24- 网站被K后,笔者做的第一件事便是在网站上增加更新模块。百度算法更新,对于网站内容给予了相当大的权重,这是笔者网站最欠缺的部分,保证了及时的更新便有了吸引蜘蛛爬取的...2016-10-10
- 我们知道百度熊抱枕很大,只想要百度熊的大头,该怎么办呢?下面我们就来看看详细的教程。 1、首先打开photoshopCS6软件,新建一个“1600*1600”的白色背景图,并从右上角...2016-12-31
如何根据百度地图计算出两地之间的驾驶距离(两种语言js和C#)
以下是使用js代码实现百度地图计算两地距离,代码如下所示:<script src="js/jquery-1.9.0.js" type="text/javascript" language="javascript"></script><script language="javascript" type="text/javascript" src="js/...2015-10-30- 用户为满足自己某种需求而来到搜索引擎的,判断用户的需求是做好网站的开始。只有准确地判断出用户需求,了解用户搜索的目的,才能合理地衡量出一个网站结果的质量好,做好搜...2016-10-10
- 网页头部head 部分:TITLE 、<mtea>部分 网站描述Description、keyword 内容中的关键词,大家优化时也都比较重视这部分的关键词优化,因为在查询搜索结果时此处出现的关键词...2017-07-06
JS实现获取来自百度,Google,soso,sogou关键词的方法
这篇文章主要介绍了JS实现获取来自百度,Google,soso,sogou关键词的方法,结合实例形式分析了js获取来路页面的方法与相关搜索引擎关键词的处理技巧,需要的朋友可以参考下...2017-01-09- /*解决代码高亮太长不换行*/ .syntaxhighlighter{word-break:break-all;} uParse('#newstext', {rootPath: '/e/extend/ueditor/'}) 用灵动标签调用最新最多评论文章: [...2016-08-27
- 这篇文章主要介绍了WinForm调用百度地图接口用法,结合具体实例形式简单分析了WinForm WebBrower控件与前端百度接口交互的相关操作技巧,需要的朋友可以参考下...2020-06-25
- 今天小编在这里就来给Illustrator的这一款软件的使用者们来说一说绘制百度云标志LOGO的教程,各位想知道具体绘制方法的使用者,那么下面就快来跟着小编一起看一看教程。...2016-09-14
- 我们一起来看一篇关于PHPCMS实现自动推送URL到百度站长平台,希望此教程能够帮助到各位朋友。 百度站长平台开放url推送接口,可以使用调用接口的形式主动及时推送u...2016-11-25
- 仅仅凭自己的感觉是根本无法判断这个关键词的价值的,那么这时候我们就可以适当的应用一下百度指数工具,利用这个工具我们可以挖掘出一些有价值的关键词。 一、从百...2016-10-10
- 这篇文章主要介绍了C# 10分钟完成百度人脸识别(入门篇),文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-06-25
- 百度不更新网站原因分析 今天我们来看一篇关于 哦,你是不是其它的之一呢,好了下面来看看各位站长总结了来百度不更新网页的原因吧。 一、首页的大flash图片。 ...2016-10-10
- 网站运营是很多人向往的赚钱方法,一些网站会发现,自己做的聚合页面和站内搜索页面被百度搜索无情打击,这是为什么,不知道原因的伙伴下面跟小编一起来看看。 今天杨子...2017-07-06
- 以前讲过很多关于curl模拟登陆用户的一些例子了,今天我来介绍一个登录百度产品的一个php程序代码,希望文章给你带来帮助,此文章只供学习使用。 最近弄了一个工具,希望...2016-11-25
- php curl的好处可以以最快的方式并且模仿post提供我们的url地址给百度搜索引擎进行收录了,下面来看一个官方的例子吧。 百度链接提交三种方式: 1、主动推送:最为快速...2016-11-25