使用PyCharm批量爬取小说的完整代码
使用pycharm批量爬取小说
爬取小说的思路:
1.获取小说地址
本文以搜书网一小说为例《嘘,梁上有王妃!》
目录网址:https://www.soshuw.com/XuLiangShangYouWangFei/
加载需要的包:
import re from bs4 import BeautifulSoup as ds import requests
获取小说目录文件,返回<Response [200]>,表示可正常爬取该网页
base_url='https://www.soshuw.com/XuLiangShangYouWangFei/' chapter_html=requests.get(base_url) print(chapter_html)
2.分析小说地址结构
解析目录网页 , 输出结果为目录网页的源代码
chapter_page_html=ds(chapter_page,'lxml') print(chapter_page)
打开目录网页,发现在正文的目录前面有一个最新章节目录(这里有九个章节),再完整的目录中是包含最新章节的,所以这里最新章节是不需要的。
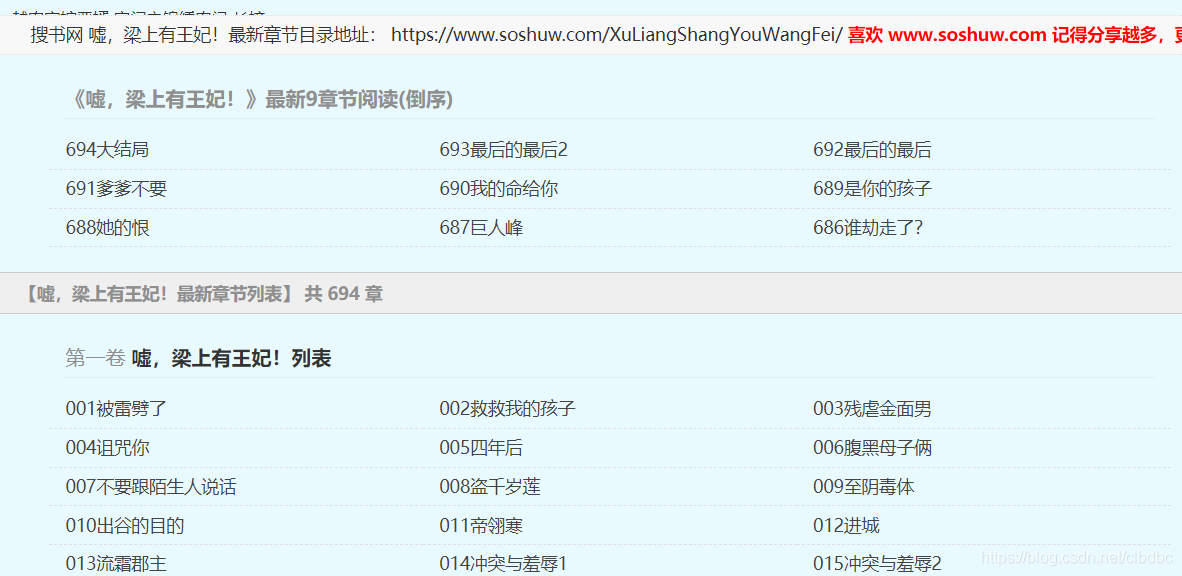
在网页单击右键选择“检查”(或者“属性”,不同的浏览器的叫法不一致,我用的是IE)选择“元素”列,鼠标再右侧代码块上移动时。左侧网页会高亮显示其对应网页区域,找到完整目录对应的代码块。如下图:
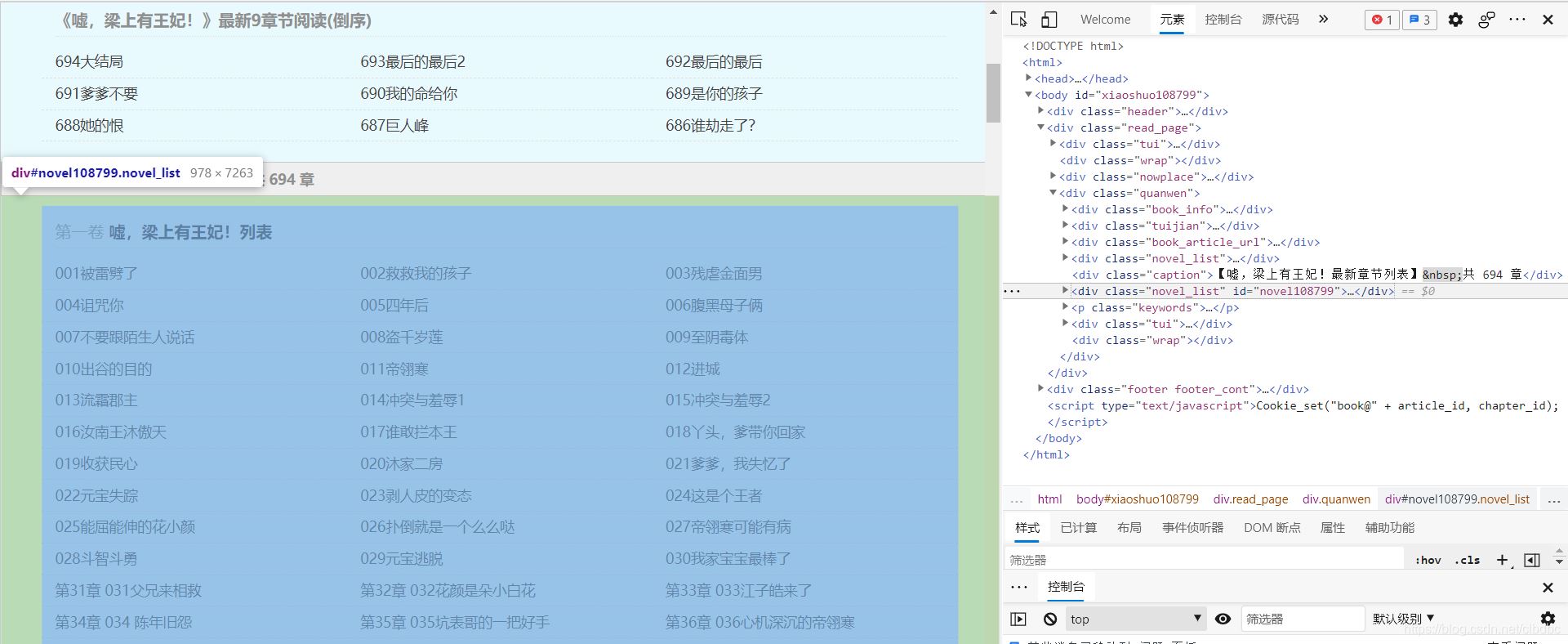
完整目录的锚有两个,分别是class="novel_list"和id=“novel108799”,仔细观察后发现class不唯一,所以我们选用id提取该块内容

将完整目录块提取出来
chapter_novel=chapter_page.find(id="novel108799") print(chapter_novel)
结果如下(仅部分结果):
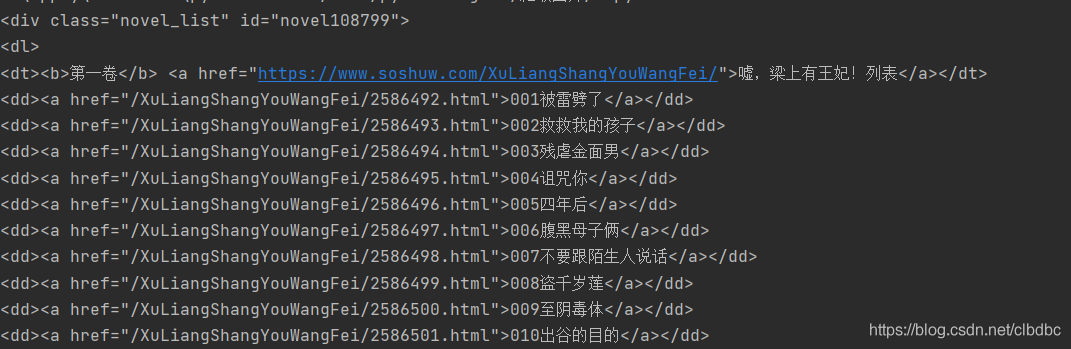
对比小说章节内容网址和目录网址(base_url)发现,我们只需要将base_url和章节内容网址的后半段拼接到一起就可以得到完整的章节内容网址
3.拼接地址
利用正则语言库将地址后半段提取出来
chapter_novel_str=str(chapter_novel) regx = '<dd><a href="/XuLiangShangYouWangFei(.*?)"' chapter_href_list = re.findall(regx, chapter_novel_str) print(chapter_href_list)
拼接url:
定义一个列表chapter_url_list接收完整地址
chapter_url_list = [] for i in chapter_href_list: url=base_url+i chapter_url_list.append(url) print(chapter_url_list)
4.分析章节内容结构
打开章节,右键→“属性”,查看内容结构,发现小说正文有class和id两个锚,class是不变的,id随着章节而变化,所以我们用class提取正文

提取正文段
chapter_novel=chapter_page.find(id="novel108799") print(chapter_novel)
提取正文文本和标题
body_html=requests.get('https://www.soshuw.com/XuLiangShangYouWangFei/3647144.html')
body_page=ds(body_html.content,'lxml')
body = body_page.find(class_='content')
body_content=str(body)
print(body_content)
body_regx='<br/> (.*?)\n'
content_list=re.findall(body_regx,body_content)
print(content_list)
title_regx = '<h1>(.*?)</h1>'
title = re.findall(title_regx, body_html.text)
print(title)
5.保存文本
with open('1.txt', 'a+') as f:
f.write('\n\n')
f.write(title[0] + '\n')
f.write('\n\n')
for e in content_list:
f.write(e + '\n')
print('{} 爬取完毕'.format(title[0]))
6.完整代码
import re
from bs4 import BeautifulSoup as ds
import requests
base_url='https://www.soshuw.com/XuLiangShangYouWangFei'
chapter_html=requests.get(base_url)
chapter_page=ds(chapter_html.content,'lxml')
chapter_novel=chapter_page.find(id="novel108799")
#print(chapter_novel)
chapter_novel_str=str(chapter_novel)
regx = '<dd><a href="/XuLiangShangYouWangFei(.*?)"'
chapter_href_list = re.findall(regx, chapter_novel_str)
#print(chapter_href_list)
chapter_url_list = []
for i in chapter_href_list:
url=base_url+i
chapter_url_list.append(url)
#print(chapter_url_list)
for u in chapter_url_list:
body_html=requests.get(u)
body_page=ds(body_html.content,'lxml')
body = body_page.find(class_='content')
body_content=str(body)
# print(body_content)
body_regx='<br/> (.*?)\n'
content_list=re.findall(body_regx,body_content)
#print(content_list)
title_regx = '<h1>(.*?)</h1>'
title = re.findall(title_regx, body_html.text)
#print(title)
with open('1.txt', 'a+') as f:
f.write('\n\n')
f.write(title[0] + '\n')
f.write('\n\n')
for e in content_list:
f.write(e + '\n')
print('{} 爬取完毕'.format(title[0]))
到此这篇关于使用PyCharm批量爬取小说的文章就介绍到这了,更多相关PyCharm批量爬取小说内容请搜索猪先飞以前的文章或继续浏览下面的相关文章希望大家以后多多支持猪先飞!
相关文章
- 这篇文章主要介绍了解决Mybatis 大数据量的批量insert问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-01-09
- 今天小编就为大家分享一篇解决Pycharm的项目目录突然消失的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-04-22
- pycharm2021激活码是一个可以轻松帮助用户免费激活pycharm2021.1软件的文件,虽然说pycharm现在只是推出了2021.1的EAP版,但是如果你想先率先体验一波,那么就可以利用小编提供的这个激活码来进行使用啦,并这个激活码是永久有效的...2021-03-30
- 这篇文章主要介绍了pycharm实现print输出保存到txt文件,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-06-02
- 这篇文章主要介绍了pycharm 实现光标快速移动到括号外或行尾的操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-02-06
- 这篇文章主要介绍了解决Pycharm 运行后没有输出的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-02-06
pycharm最新免费激活码分享(无须破解,复制粘贴即可 21.4.20亲测可用)
这篇文章主要介分享了pycharm的最新激活码,帮助大家更好的免费使用此IDE,感兴趣的朋友可以了解下...2021-04-20- 这篇文章主要介绍了在PyCharm中安装PaddlePaddle的方法,本文给大家介绍的非常想详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-02-05
- 这篇文章主要介绍了Python爬取微信小程序通用方法代码实例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下...2020-09-29
- 这篇文章主要介绍了Pycharm 设置默认解释器路径和编码格式的操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-02-05
详解pycharm的python包opencv(cv2)无代码提示问题的解决
这篇文章主要介绍了详解pycharm的python包opencv(cv2)无代码提示问题的解决,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2021-01-29- 这篇文章主要介绍了Pycharm 跳转回之前所在页面的操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-02-05
- 这篇文章主要介绍了Pycharm 如何一键加引号的方法步骤,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2021-02-05
- 这篇文章主要介绍了基于Pycharm加载多个项目过程图解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下...2020-04-22
- 这篇文章主要介绍了pycharm激活方法到2099年,文末给大家提到了idea和pycharm最新版激活方法,非常不错对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2020-09-15
解决pycharm下载库时出现Failed to install package的问题
很多小伙伴遇到pycharm下载库时出现Failed to install package不知道怎么解决,下面小编给大家带来了解决方法,需要的朋友参考下吧...2021-09-04- 这篇文章主要介绍了PyCharm设置注释字体颜色以及是否倾斜的操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-09-16
- 这篇文章主要介绍了pycharm 复制代码出现空格的解决方式,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-01-16
基于Python-Pycharm实现的猴子摘桃小游戏(源代码)
这篇文章主要介绍了基于Python-Pycharm实现的猴子摘桃小游戏,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-02-20- 本篇文章主要介绍了node.js爬虫爬取拉勾网职位信息的方法。具有很好的参考价值。下面跟着小编一起来看下吧 用node.js写了一个简单的小爬虫,用来爬取拉勾网上的招...2017-07-06