Python用requests模块实现动态网页爬虫
前言
Python爬虫实战,requests模块,Python实现动态网页爬虫
让我们愉快地开始吧~
开发工具
Python版本: 3.6.4
相关模块:
urllib模块;
random模块;
requests模块;
traceback模块;
以及一些Python自带的模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
那我们就开启爬虫的正确姿势吧,先用解析接口的方法来写爬虫。
首先,找到真实请求。右键检查,点击Network,选中XHR,刷新网页,选择Name列表中的jsp文件。没错,就这么简单,真实请求就藏在里面。

我们再仔细看看这个jsp,这简直是个宝啊。有真实请求url,有请求方法post,有Headers,还有Form Data,而From Data表示给url传递的参数,通过改变参数,咱们就可以获得数据!为了安全,给自个Cookie打了个马赛克
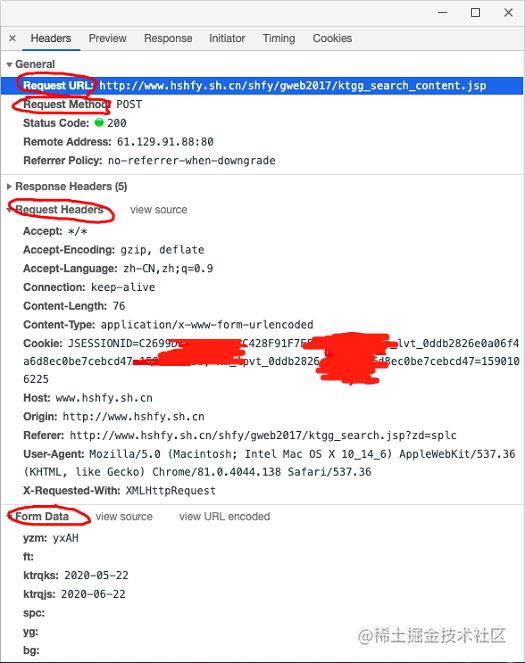
我们尝试点击翻页,发现只有pagesnum参数会变化。

1 from urllib.parse import urlencode 2 import csv 3 import random 4 import requests 5 import traceback 6 from time import sleep 7 from lxml import etree #lxml为第三方网页解析库,强大且速度快
1 base_url = 'http://www.hshfy.sh.cn/shfy/gweb2017/ktgg_search_content.jsp?' #这里要换成对应Ajax请求中的链接
2
3 headers = {
4 'Connection': 'keep-alive',
5 'Accept': '*/*',
6 'X-Requested-With': 'XMLHttpRequest',
7 'User-Agent': '你的User-Agent',
8 'Origin': 'http://www.hshfy.sh.cn',
9 'Referer': 'http://www.hshfy.sh.cn/shfy/gweb2017/ktgg_search.jsp?zd=splc',
10 'Accept-Language': 'zh-CN,zh;q=0.9',
11 'Content-Type': 'application/x-www-form-urlencoded',
12 'Cookie': '你的Cookie'
13 }
构建get_page函数,自变量为page,也就是页数。以字典类型创建表单data,用post方式去请求网页数据。这里要注意要对返回的数据解码,编码为’gbk’,否则返回的数据会乱码!
1def get_page(page):
2 n = 3
3 while True:
4 try:
5 sleep(random.uniform(1, 2)) # 随机出现1-2之间的数,包含小数
6 data = {
7 'yzm': 'yxAH',
8 'ft':'',
9 'ktrqks': '2020-05-22',
10 'ktrqjs': '2020-06-22',
11 'spc':'',
12 'yg':'',
13 'bg':'',
14 'ah':'',
15 'pagesnum': page
16 }
17 url = base_url + urlencode(data)
18 print(url)
19 try:
20 response = requests.request("POST",url, headers = headers)
21 #print(response)
22 if response.status_code == 200:
23 re = response.content.decode('gbk')
24 # print(re)
25 return re # 解析内容
26 except requests.ConnectionError as e:
27 print('Error', e.args) # 输出异常信息
28 except (TimeoutError, Exception):
29 n -= 1
30 if n == 0:
31 print('请求3次均失败,放弃此url请求,检查请求条件')
32 return
33 else:
34 print('请求失败,重新请求')
35 continue
构建parse_page函数,对返回的网页数据进行解析,用Xpath提取所有字段内容,保存为csv格式。
1def parse_page(html):
2 try:
3 parse = etree.HTML(html) # 解析网页
4 items = parse.xpath('//*[@id="report"]/tbody/tr')
5 for item in items[1:]:
6 item = {
7 'a': ''.join(item.xpath('./td[1]/font/text()')).strip(),
8 'b': ''.join(item.xpath('./td[2]/font/text()')).strip(),
9 'c': ''.join(item.xpath('./td[3]/text()')).strip(),
10 'd': ''.join(item.xpath('./td[4]/text()')).strip(),
11 'e': ''.join(item.xpath('./td[5]/text()')).strip(),
12 'f': ''.join(item.xpath('./td[6]/div/text()')).strip(),
13 'g': ''.join(item.xpath('./td[7]/div/text()')).strip(),
14 'h': ''.join(item.xpath('./td[8]/text()')).strip(),
15 'i': ''.join(item.xpath('./td[9]/text()')).strip()
16 }
17 #print(item)
18 try:
19 with open('./law.csv', 'a', encoding='utf_8_sig', newline='') as fp:
20 # 'a'为追加模式(添加)
21 # utf_8_sig格式导出csv不乱码
22 fieldnames = ['a', 'b', 'c', 'd', 'e','f','g','h','i']
23 writer = csv.DictWriter(fp,fieldnames)
24 writer.writerow(item)
25 except Exception:
26 print(traceback.print_exc()) #代替print e 来输出详细的异常信息
27 except Exception:
28 print(traceback.print_exc())
遍历一下页数,调用一下函数
1 for page in range(1,5): #这里设置想要爬取的页数
2 html = get_page(page)
3 #print(html)
4 print("第" + str(page) + "页提取完成")
效果:
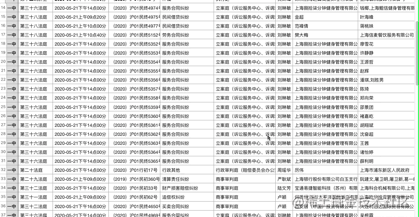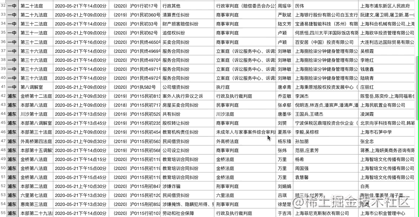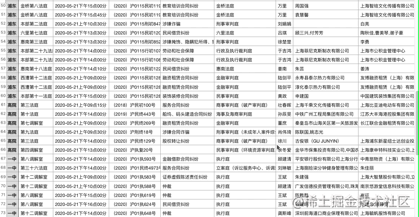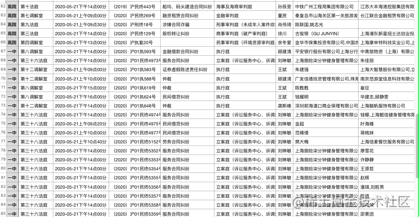
总结
到此这篇关于Python用requests模块实现动态网页爬虫的文章就介绍到这了,更多相关Python requests内容请搜索猪先飞以前的文章或继续浏览下面的相关文章希望大家以后多多支持猪先飞!
原文出处:https://blog.csdn.net/m0_59162248/article/details/122875682
相关文章
- 这篇文章主要介绍了python-opencv-画外接矩形框的实例代码,代码简单易懂,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-09-04
Python astype(np.float)函数使用方法解析
这篇文章主要介绍了Python astype(np.float)函数使用方法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下...2020-06-08- 2022虎年新年即将来临,小编为大家带来了一个利用Python编写的虎年烟花特效,堪称全网最绚烂,文中的示例代码简洁易懂,感兴趣的同学可以动手试一试...2022-02-14
- 在本篇文章里小编给大家分享的是一篇关于python中numpy.empty()函数实例讲解内容,对此有兴趣的朋友们可以学习下。...2021-02-06
python-for x in range的用法(注意要点、细节)
这篇文章主要介绍了python-for x in range的用法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-05-10- 这篇文章主要介绍了Python 图片转数组,二进制互转操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-09
- 这篇文章主要介绍了Python中的imread()函数用法说明,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-16
- 这篇文章主要介绍了python如何实现b站直播自动发送弹幕,帮助大家更好的理解和学习使用python,感兴趣的朋友可以了解下...2021-02-20
python Matplotlib基础--如何添加文本和标注
这篇文章主要介绍了python Matplotlib基础--如何添加文本和标注,帮助大家更好的利用Matplotlib绘制图表,感兴趣的朋友可以了解下...2021-01-26- 这篇文章主要介绍了解决python 使用openpyxl读写大文件的坑,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-13
- 今天小编就为大家分享一篇python 计算方位角实例(根据两点的坐标计算),具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-04-27
- 这篇文章主要为大家详细介绍了python实现双色球随机选号,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下...2020-05-02
- 在本篇文章里小编给大家整理的是一篇关于python中使用np.delete()的实例方法,对此有兴趣的朋友们可以学习参考下。...2021-02-01
- 这篇文章主要介绍了使用Python的pencolor函数实现渐变色功能,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-03-09
- 这篇文章主要介绍了python自动化办公操作PPT的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2021-02-05
Python getsizeof()和getsize()区分详解
这篇文章主要介绍了Python getsizeof()和getsize()区分详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-11-20- 这篇文章主要为大家详细介绍了python实现学生通讯录管理系统,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下...2021-02-25
- 这篇文章主要介绍了PyTorch一小时掌握之迁移学习篇,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-09-08
- 这篇文章主要介绍了解决python 两个时间戳相减出现结果错误的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-12
- 这篇文章主要介绍了Python绘制的爱心树与表白代码,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-04-06