低配硬件不能运行深度神经网络?手把手教你克服“杀牛用鸡刀”难题
如果对深度学习有所了解的小伙伴们想必都知道,深度学习需要使用强大的服务器、加速嵌入式平台(如 NVIDIA 的 Jetson)来运行深度学习算法,然而这也同样意味着不菲的开支。
那么问题来了,如果你想你想用树莓派来做一个目标跟踪器,为你看家守院,这可以实现吗?换句话说,如果你需要在不带加速器的 ARM CPU 上运行卷积神经网络了怎么办?
雷锋网想,大概就会像下图这位小哥一样,处境尴尬。

来自德国初创企业 BuddyGuard GmbH 的机器学习工程师 Dmytro Prylipko 就为我们提供了一个可行的“杀牛不用鸡刀”的解决方案,雷锋网编译,未经许可不得转载。
如何优化推理时间?
机器学习社区为缩短神经网络的推理时间,已经研究了一段时间,研究得出可行的解决方案还是相当多的。本文将尝试回答一个简单的问题:什么库/工具包/框架可以帮助我们优化训练模型的推理时间?本文只讨论已为 ARM 架构芯片提供 C / C ++ 接口的工具包和库(由于嵌入式设备上使用 ,我们很少 Lua 或 Python),限于文章篇幅,不阐述另外一种加速神经网络推理的方法,即修改网络架构,从 SqeezeNet 架构可看出,修改网络架构是一个可行的方案。基于上述原因,本文涉及的实验只涉及使用 Caffe,TensorFlow 和 MXNet 这 3 个开源的深度学习框架。
加速神经网络模型在硬件平台计算速度,两个主要有大的策略:
1)修改神经网络的模型;
2)加快框架运行速度。
当然,将这两个策略结合起来使用,也是一种不错的思路。
修改神经网络模型有两种方法,一是通过降低权重精度实现,即降低特征量化的精度,二是通过权重剪枝来实现,权重剪枝的背后的思想是降低系统参数的冗余。降低权重低精度通常采用(用定点数或动态定点数表示浮点数的方法,支持这种做法的原理是:推理过程并不需要高精度,因为在运算过程中,计算的线性性质和非线性的动态范围压缩,使得量化误差仅在子线性地(sub-linearly)范围内传递,从而不会引起数值的剧烈变动。更进一步,我们可以使用低精度乘法来训练神经网络模型。结合 SIMD 指令集,比如 SSE3,可以使特征量化过程可以更为高效,从而加速训练过程。然而,目前我们还很难找到同时使用了这两者的解决方案。比如使用 Ristretto 框架可以执行有限精度的自动量化,但它却并没有降低计算负载。TensorFlow 也可以执行量化,但其推理时间实际上却增加了 5 到 20 倍,因为 TensorFlow 还引入了辅助量化/去量化的计算节点。因此在实际操作中,我们只把量化作为压缩网络权重的方法,当存储空间有限时可以这样操作,至少这已经是当前最先进的技术。
从另外一个角度看,我们可采用加快框架的执行时间的方法,这种方法不会影响到模型的参数。这种策略主要上采用优化矩阵之间的乘法(GEMM)类的通用计算技巧,从而同时影响卷积层(其计算通常是 im2col + GEMM)和全连接层。除此之外,可以使用神经网络的加速包 NNPACK,就个人理解,NNPACK 的核心思路是使用快速傅里叶变换将时间域中的卷积运算转换成了频域中的乘法运算。
加快框架执行速度另一种方法是将网络模型和权重配置转换成针对目标平台代码,并对代码进行优化,而不是让它们直接在某一个框架内运行。这种方法的典型案例是 TensorRT。还有 CaffePresso, 可以将 Caffe 中 prototxt 类型的文件定制成适用于各种不同硬件平台的低规格版本。然而,TensorRT 的运行需要 CUDA,而且只能在 NVIDIA 的 GPU 中才能使用,而 CaffePresso 也需要某种硬件加速器(DSP、FPGA 或 NoC),所以这两种方法都不适合用于我的测试硬件——树莓派。
上述内容仔细地评估现有的解决办法后,我发现以下几种方法能够加速当前流行的可用模型的推理:
如果你的框架中使用了 OpenBLAS(基础线性代数程序集的开源实现),你可以尝试使用其为深度学习进行过优化的分支: https://github.com/xianyi/OpenBLAS/tree/optimized_for_deeplearning
NNPACK 能和其他一些框架(包括 Torch、Caffe 和 MXNet)联合使用:http://github.com/Maratyszcza/NNPACK
将 TensorFlow 编译为在树莓派平台的目标代码时,你可以使用一些编译优化标志,从而充分利用 NEON 指令集加速目标代码的执行速度:http://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/makefile#raspberry-pi
基于以上 3 种方法,我概括出以下调测配置:
1. 使用以 OpenBLAS 为后端的 Caffe 主分支(caffe-openblas);
2. 使用以 OpenBLAS 为后端 OpenBLAS 且为深度学习优化过的 Caffe 分支版本(caffe-openblas-dl);
3. 编译 TensorFlow 时,使用优化编译标志 OPTFLAGS="-Os" (tf-vanilla)
4. 编译 TensorFlow 时,使用优化编译标志 OPTFLAGS="-Os -mfpu=neon-vfpv4 -funsafe-math-optimizations -ftree-vectorize" (tf-neon-vfpv4)
5. 使用以 OpenBLAS 实现基础线性代数程序集的 Vanilla MXNet
6. 使用带有 OpenBLAS 、且为深度学习优化过 MXNet 分支版本(mxnet-openblas-dl)。
你可能会疑惑:配置中怎么没有 NNPACK?这确实有点复杂,由 ajtulloch 创建的 Caffe 分支提供了最直接的使用 NNPACK 方法。然而自从它被集成进去以后,NNPACK 的 API 接口就已经改变了,并且目前我无法编译它。Caffe2 对 NNPACK 有原生支持,但我不会考虑 Caffe2,因为它处于实验性阶段并且几乎对 Caffe 进行了尚未文档化的重构。另外一个选项就是使用 Maratyszcza 的 caffe-nnpack 分支,但该分支比较老旧且已经停止维护。
另外一个问题就是出于 NNPACK 本身。它只提供了 Android/ARM 平台的交叉编译配置,并不提供在 Linux/ARM 平台上的交叉编译配置。结合 MXNet,我尝试编译目标平台代码,但结果无法在目标平台上正常运行。我只能在台式电脑上运行它,但是我并没有看到比 OpenBLAS 会有更好的性能。由于我的目标是评估已经可用的解决方法,所以我只能推迟 NNPACK 的实验了。
以上所有的这些方法都是在四核 1.3 GHz CPU 和 1 GB RAM 的树莓派 3 上执行。操作系统是 32 位的 Raspbian,所以检测到的 CPU 不是 ARMv8 架构,而是 ARMv7 架构。硬件规格如下:
model name : ARMv7 Processor rev 4 (v7l)
BogoMIPS : 38.40
Features : half thumb fastmult vfp edsp neon vfpv3 tls vfpv4 idiva idivt vfpd32 lpae evtstrm crc32
CPU implementer : 0x41
CPU architecture: 7
CPU variant : 0x0
CPU part : 0xd03
CPU revision : 4
为了评估上述每个测试配置的性能,我制定的测试方案如下:使用相同的神经网络。也就是一个有 3 个卷积层和 2 个全连接层且在顶层带有 Softmax 的小型卷积神经网络:
conv1: 16@7x7
relu1pool1: MAX POOL 2x2conv2: 48@6x6
relu2pool2: MAX POOL 3x3conv3: 96@5x5
relu3fc1: 128 unitsfc2: 848 units
softmax
该卷积神经网络有 1039744 个参数。虽然非常小,但它已经足够强大了,可以用来处理许多计算机视觉算法。该网络使用 Caffe 进行训练人脸识别任务,并将其转换为 TensorFlow 和 MXNet 格式,从而使用这些框架进行评估。批量执行次数对性能有很大的影响,为了测量前向通过时间(forward pass time),我们将批量执行的次数设置为 1 到 256。在不同次数的批量执行中,我们每次执行 100 次前向通过,并计算了每一张图像的平均处理时间。
评估结果和讨论
在下面的表格中,列出了平均前向通过的时间。其中,A 是 caffe-openblas, B 是 caffe-openblas-dl, C 代表 tf-vanilla, D 是 tf-neon-vfpv4, E 是 mxnet-openblas, F 是 mxnet-openblas-dl。
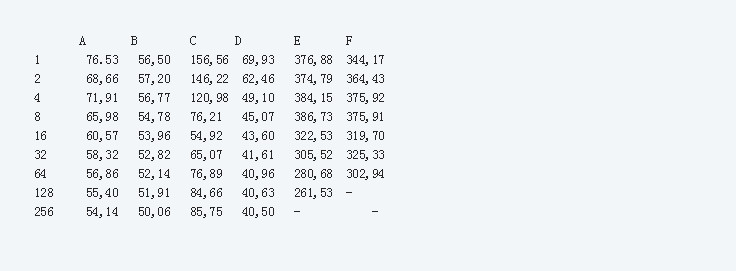
表 1 不同测试配置在不同的批处理次数下的性能表现

图 1 线性尺度下不同配置的前向通过时间比较
在对数尺度尺度上我们再来看一下:
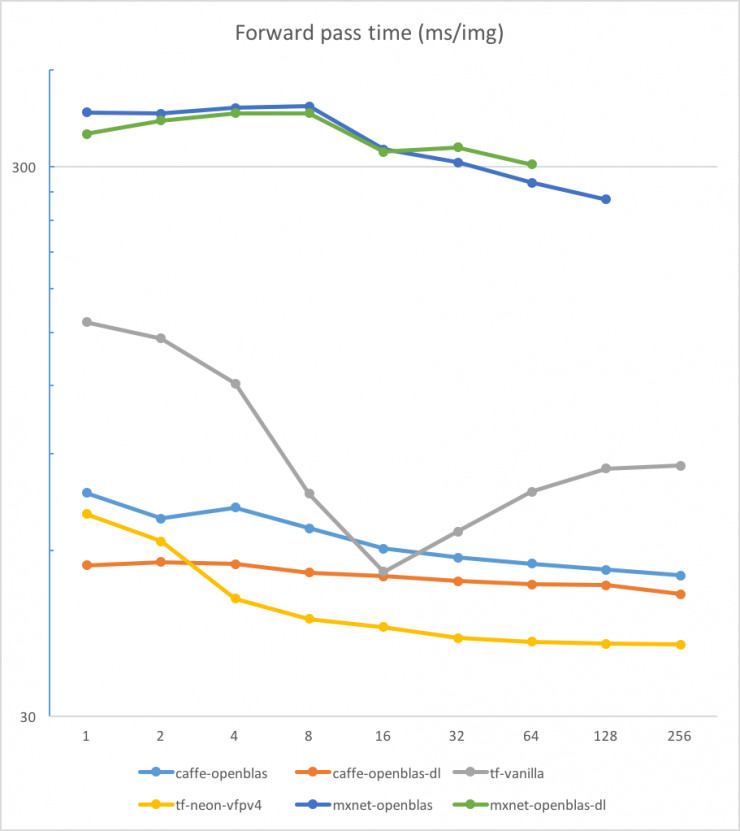
图 2 对数尺度下不同配置的前向通过时间比较
测试结果让我大吃一惊。首先,我没有预料到在 CPU 上运行 MXNet 的性能会这么差。但这看起来已经是一个众所周知的问题。此外,受限于存储空间,它无法运行 256 张图片的批处理。第二个惊奇是优化过的 TensorFlow 竟有如此好的性能。它甚至比 Caffe 的表现还好(批处理次数超过 2 时),光从原始框架上看是很难预料这个结果的。需要注意的是,上述测试配置中的优化标志并不是在任意 ARM 芯片上都可以使用的。
Caffe 因速度非常快和思路独到而知名。如果你需要连续地处理图片,可以选择使用优化过的 OpenBLAS 的 Caffe,可得到最好的处理性能。如果想提升 10ms 的性能,你所要做的就只是简单的输入以下指令:
cd OpenBLAS
git checkout optimized_for_deeplearning
为了将我的研究转变成正式的东西,我仍需要做大量的工作:评估更多的模型,最终集成 NNPACK,以及研究更多结合了 BLAS 后端的框架。希望本文能帮助你了解目前最流行的解决方案的推理速度。
相关文章
- 虽然AlexNet证明深层神经网络卓有成效,但它没有提供一个通用的模板来指导后续的研究人员设计新的网络。下面,我们将介绍一些常用于设计深层神经网络的启发式概念...2021-10-11
- 这篇文章主要介绍了利用keras使用神经网络预测销量操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-07-08
- 这篇文章主要为大家介绍了TensorFlow神经网络学习的基本知识张量与变量概念详解,有需要的朋友可以借鉴参考下,希望能够有所帮助...2021-10-17
低配硬件不能运行深度神经网络?手把手教你克服“杀牛用鸡刀”难题
如果对深度学习有所了解的小伙伴们想必都知道,深度学习需要使用强大的服务器、加速嵌入式平台(如 NVIDIA 的 Jetson)来运行深度学习算法,然而这也同样意味着不菲的开支。...2017-01-22- 这篇文章主要为大家讲解了Python深度学习中的pytorch卷积神经网络LeNet的示例解析,有需要的朋友可以借鉴参考下希望能够有所帮助...2021-10-11
- 这篇文章主要介绍了使用Keras画神经网络准确性图教程,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-06-16
- 今天小编就为大家分享一篇Pytorch实现神经网络的分类方式,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-04-29
Pytorch 搭建分类回归神经网络并用GPU进行加速的例子
今天小编就为大家分享一篇Pytorch 搭建分类回归神经网络并用GPU进行加速的例子,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-04-27- 今天带大家学习如何使用Python实现卷积神经网络,这是个很难的知识点,文中有非常详细的介绍,对小伙伴们很有帮助,需要的朋友可以参考下...2021-06-04
- 在本篇文章里小编给大家整理的是一篇关于如何在Python中创建一个简单的神经网络的相关知识点,有兴趣的朋友们可以参考下。...2021-01-04
- 今天小编就为大家分享一篇关于pytorch中全连接神经网络搭建两种模式详解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-04-27
- 这篇文章主要介绍了Python利用全连接神经网络求解MNIST问题,结合实例形式详细分析了单隐藏层神经网络与多层神经网络,以及Python全连接神经网络求解MNIST问题相关操作技巧,需要的朋友可以参考下...2020-04-27
python神经网络TensorFlow简介常用基本操作教程
这篇文章主要介绍了python神经网络入门TensorFlow简介常用基本操作教程,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步...2021-11-03- 今天小编就为大家分享一篇pytorch下使用LSTM神经网络写诗实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-04-27
- 这篇文章主要介绍了Python使用循环神经网络解决文本分类问题的方法,结合实例形式详细分析了Python神经网络相关概念、原理及解决文本分类具体操作技巧,需要的朋友可以参考下...2020-04-27
- 这篇文章主要为大家介绍了Python深度学习中TensorFlow神经网络基础概括,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步...2021-10-17
Python编程pytorch深度卷积神经网络AlexNet详解
AlexNet和LeNet的架构非常相似。这里我们提供了一个稍微精简版本的AlexNet,去除了当年需要两个小型GPU同时运算的设计特点...2021-10-11- 今天小编就为大家分享一篇pytorch-神经网络拟合曲线实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-04-27
- 这学期修了一门机器视觉的选修课,课设要是弄一个花卉识别的神经网络,所以我网上找了开源代码进行了修改,最后成功跑起来,结果只有一个准确率(94%)既然都跑了这个神经网络的代码,那么干脆就把这个神经网络真正的使用起来,把这个神经网络弄成一个可视化界面...2021-06-20
- 今天小编就为大家分享一篇关于基于MATLAB神经网络图像识别的高识别率代码,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧...2020-04-25