整理的可以直接用的18个PHP代码函数片段
每位程序员和开发者都喜欢讨论他们最爱的代码片段,尤其是当PHP开发者花费数个小时为网页编码或创建应用时,他们更知道这些代码的重要性。为了节约编码时间,笔者收集了一些较为实用的代码片段,帮助开发者提高工作效率。>>>
1) Whois query using PHP ——利用PHP获取Whois请求
利用这段代码,在特定的域名里可获得whois信息。把域名名称作为参数,并显示所有域名的相关信息。
| 代码如下 | 复制代码 |
| function whois_query($domain) { // fix the domain name: $domain = strtolower(trim($domain)); $domain = preg_replace('/^http:///i', '', $domain); $domain = preg_replace('/^www./i', '', $domain); $domain = explode('/', $domain); $domain = trim($domain[0]); // split the TLD from domain name $_domain = explode('.', $domain); $lst = count($_domain)-1; $ext = $_domain[$lst]; // You find resources and lists // like these on wikipedia: // // <a href="http://de.wikipedia.org/wiki/Whois">http://de.wikipedia.org/wiki/Whois</a> // $servers = array( "biz" => "whois.neulevel.biz", "com" => "whois.internic.net", "us" => "whois.nic.us", "coop" => "whois.nic.coop", "info" => "whois.nic.info", "name" => "whois.nic.name", "net" => "whois.internic.net", "gov" => "whois.nic.gov", "edu" => "whois.internic.net", "mil" => "rs.internic.net", "int" => "whois.iana.org", "ac" => "whois.nic.ac", "ae" => "whois.uaenic.ae", "at" => "whois.ripe.net", "au" => "whois.aunic.net", "be" => "whois.dns.be", "bg" => "whois.ripe.net", "br" => "whois.registro.br", "bz" => "whois.belizenic.bz", "ca" => "whois.cira.ca", "cc" => "whois.nic.cc", "ch" => "whois.nic.ch", "cl" => "whois.nic.cl", "cn" => "whois.cnnic.net.cn", "cz" => "whois.nic.cz", "de" => "whois.nic.de", "fr" => "whois.nic.fr", "hu" => "whois.nic.hu", "ie" => "whois.domainregistry.ie", "il" => "whois.isoc.org.il", "in" => "whois.ncst.ernet.in", "ir" => "whois.nic.ir", "mc" => "whois.ripe.net", "to" => "whois.tonic.to", "tv" => "whois.tv", "ru" => "whois.ripn.net", "org" => "whois.pir.org", "aero" => "whois.information.aero", "nl" => "whois.domain-registry.nl" ); if (!isset($servers[$ext])){ die('Error: No matching nic server found!'); } $nic_server = $servers[$ext]; $output = ''; // connect to whois server: if ($conn = fsockopen ($nic_server, 43)) { fputs($conn, $domain."rn"); while(!feof($conn)) { $output .= fgets($conn,128); } fclose($conn); } else { die('Error: Could not connect to ' . $nic_server . '!'); } return $output; } |
|
2) Text messaging with PHP using the TextMagic API ——使用TextMagic API 获取PHP Test信息
TextMagic引入强大的核心API,可轻松将SMS发送到手机。该API是需要付费。
| 代码如下 | 复制代码 |
| the TextMagic PHP lib require('textmagic-sms-api-php/TextMagicAPI.php'); // Set the username and password information $username = 'myusername'; $password = 'mypassword'; // Create a new instance of TM $router = new TextMagicAPI(array( 'username' => $username, 'password' => $password )); // Send a text message to '999-123-4567' $result = $router->send('Wake up!', array(9991234567), true); // result: Result is: Array ( [messages] => Array ( [19896128] => 9991234567 ) [sent_text] => Wake up! [parts_count] => 1 ) |
|
3) Get info about your memory usage——获取内存使用率
这段代码帮助你获取内存使用率。
| 代码如下 | 复制代码 |
| echo "Initial: ".memory_get_usage()." bytes n"; /* prints Initial: 361400 bytes */ // let's use up some memory for ($i = 0; $i < 100000; $i++) { $array []= md5($i); } // let's remove half of the array for ($i = 0; $i < 100000; $i++) { unset($array[$i]); } echo "Final: ".memory_get_usage()." bytes n"; /* prints Final: 885912 bytes */ echo "Peak: ".memory_get_peak_usage()." bytes n"; /* prints Peak: 13687072 bytes */ |
|
4) Display source code of any webpage——查看任意网页源代码
如果你想查看网页源代码,那么只需更改第二行的URL,源代码就会在网页上显示出。
| 代码如下 | 复制代码 |
| <?php // display source code $lines = file('http://google.com/'); foreach ($lines as $line_num => $line) { // loop thru each line and prepend line numbers echo "Line #{$line_num} : " . htmlspecialchars($line) . " n"; } |
|
5) Create data uri’s——创建数据uri
通过使用此代码,你可以创建数据Uri,这对在HTML/CSS中嵌入图片非常有用,可帮助节省HTTP请求。
| 代码如下 | 复制代码 |
| function data_uri($file, $mime) { $contents=file_get_contents($file); $base64=base64_encode($contents); echo "data:$mime;base64,$base64"; } |
|
6) Detect location by IP——通过IP检索出地理位置
这段代码帮助你查找特定的IP,只需在功能参数上输入IP,就可检测出位置。
| 代码如下 | 复制代码 |
| function detect_city($ip) { $default = 'UNKNOWN'; if (!is_string($ip) || strlen($ip) < 1 || $ip == '127.0.0.1' || $ip == 'localhost') $ip = '8.8.8.8'; $curlopt_useragent = 'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.2) Gecko/20100115 Firefox/3.6 (.NET CLR 3.5.30729)'; $url = 'http://ipinfodb.com/ip_locator.php?ip=' . urlencode($ip); $ch = curl_init(); $curl_opt = array( CURLOPT_FOLLOWLOCATION => 1, CURLOPT_HEADER => 0, CURLOPT_RETURNTRANSFER => 1, CURLOPT_USERAGENT => $curlopt_useragent, CURLOPT_URL => $url, CURLOPT_TIMEOUT => 1, CURLOPT_REFERER => 'http://' . $_SERVER['HTTP_HOST'], ); curl_setopt_array($ch, $curl_opt); $content = curl_exec($ch); if (!is_null($curl_info)) { $curl_info = curl_getinfo($ch); } curl_close($ch); if ( preg_match('{ City : ([^<]*) }i’, $content, $regs) ) { $city = $regs[1]; } if ( preg_match(‘{ State/Province : ([^<]*) }i’, $content, $regs) ) { $state = $regs[1]; } if( $city!=” && $state!=” ){ $location = $city . ‘, ‘ . $state; return $location; }else{ return $default; } } |
|
7) Detect browser language——查看浏览器语言
检测浏览器使用的代码脚本语言。
| 代码如下 | 复制代码 |
| function get_client_language($availableLanguages, $default='en'){ if (isset($_SERVER['HTTP_ACCEPT_LANGUAGE'])) { $langs=explode(',',$_SERVER['HTTP_ACCEPT_LANGUAGE']); foreach ($langs as $value){ $choice=substr($value,0,2); if(in_array($choice, $availableLanguages)){ return $choice; } } } return $default; } |
|
8) Check if server is HTTPS——检测服务器是否是HTTPS
| 代码如下 | 复制代码 |
| if ($_SERVER['HTTPS'] != "on") { echo "This is not HTTPS"; }else{ echo "This is HTTPS"; } |
|
9) Generate CSV file from a PHP array——在PHP数组中生成.csv 文件
| 代码如下 | 复制代码 |
| function generateCsv($data, $delimiter = ',', $enclosure = '"') { $handle = fopen('php://temp', 'r+'); foreach ($data as $line) { fputcsv($handle, $line, $delimiter, $enclosure); } rewind($handle); while (!feof($handle)) { $contents .= fread($handle, 8192); } fclose($handle); return $contents; } |
|
一、查看邮件是否已被阅读
当你在发送邮件时,你或许很想知道该邮件是否被对方已阅读。这里有段非常有趣的代码片段能够显示对方IP地址记录阅读的实际日期和时间。
| 代码如下 | 复制代码 |
<? |
|
二、从网页中提取关键字
一段伟大的代码片段能够轻松的从网页中提取关键字。
| 代码如下 | 复制代码 |
$meta = get_meta_tags('http://www.emoticode.net/');
|
|
三、查找页面上的所有链接
使用DOM,你可以轻松从任何页面上抓取链接,代码示例如下:
| 代码如下 | 复制代码 |
$html = file_get_contents('http://www.php100.com');
|
|
四、自动转换URL,跳转至超链接
在WordPress中,如果你想自动转换URL,跳转至超链接页面,你可以利用内置的函数make_clickable()执行此操作。如果你想基于WordPress之外操作该程序,那么你可以参考wp-includes/formatting.php源代码。
| 代码如下 | 复制代码 |
function _make_url_clickable_cb($matches) {
|
|
五、创建数据URL
数据URL可以直接嵌入到HTML/CSS/JS中,以节省大量的 HTTP请求。 下面的这段代码可利用$file轻松创建数据URL。
| 代码如下 | 复制代码 |
function data_uri($file, $mime) {
|
|
六、从服务器上下载&保存一个远程图片
当你在搭建网站时,从远程服务器下载某张图片并且将其保存在自己的服务器上,这一操作会经常用到。代码如下:
| 代码如下 | 复制代码 |
$image = file_get_contents('http://www.php100.com/image.jpg');
|
|
七、移除Remove Microsoft Word HTML Tag
当你使用Microsoft Word会创建许多Tag,比如font,span,style,class等。这些标签对于Word本身而言是非常有用的,但是当你从Word粘贴至网页时,你会发现很多无用的Tag。因此,下面的这段代码可帮助你删除所有无用的Word HTML Tag。
| 代码如下 | 复制代码 |
function cleanHTML($html) {
|
|
八、检测浏览器语言
如果你的网站上有多种语言,那么可以使用这段代码作为默认的语言来检测浏览器语言。该段代码将返回浏览器客户端使用的初始语言。
| 代码如下 | 复制代码 |
function get_client_language($availableLanguages, $default='en'){
|
|
九、显示Facebook 粉丝数量
如果你的网站或者博客上有内链的Facebook页面,你或许想知道拥有多少粉丝。这段代码将帮助你查看Facebook粉丝数,记住,别忘了在你的页面ID第二行添加该段代码。
| 代码如下 | 复制代码 |
<?php |
|
PHP分配上传文件的路径实例
主要程序片段如下:
| 代码如下 | 复制代码 |
| <?php /*数字方式分配路径*/ function allotPath($id, $extend='jpg') { $folders = str_split(sprintf("%012s", $id),3); $folders[3] = $id; return '/'. join('/', $folders).'.'.$extend; } /*杂凑方式分配路径*/ function allotHashPath($id, $extend='jpg') { $folders = array_slice( str_split(md5($id),2), 0, 4); $folders[] = $id; return '/'. join('/', $folders).'.'.$extend; } var_dump(allotPath(122333)); // string(23) "/000/000/122/122333.jpg" var_dump(allotHashPath(122333)); // string(23) "/9c/7c/c2/cd/122333.jpg" | |
这里我们讲的主要是数方式分配路径及杂凑方式分配路径,我们还可以根据日期来分配,这个问题留给读者自己去实现。
php去除字符串中的HTML标签方法有很多的今天在做一个采集小功能时发现了有N种方法,下面我为各位整理一下有原创的也有整理的,希望对大家有帮助。先来看自己的写法
| 代码如下 | 复制代码 |
|
str_replace("<div class=\"summary-text\">",'',str_replace('</div>','',str_replace('</div>','',$vv))) | |
这个最简单就是替换$vv变量中指定的两个div了,后来发现有一个办法
| 代码如下 | 复制代码 |
|
$info = strip_tags($vv); | |
发现替换了所有html标签了,一面来看看strip_tags函数
trip_tags(string,allow):函数剥去 HTML、XML 以及 PHP 的标签。
| 代码如下 | 复制代码 |
|
$str = '郭碗瓢盆-<span style="color:#f00;">PHP</span>'; | |
由上面可以知道,在PHP中只能保留一些html标签,而不能指定删除一些html标签,于是我自己动手写一个放我平时的lib库文件中了。
| 代码如下 | 复制代码 |
|
| |
参数说明
$str — 是指需要过滤的一段字符串,比如div、p、em、img等html标签。
$tags — 是指想要移除指定的html标签,比如a、img、p等。
$stripContent = FALSE — 移除标签内的内容,比如将整个链接删除等,默认为False,即不删除标签内的内容。
使用说明
| 代码如下 | 复制代码 |
|
$target = strip_only_tags($source, array(‘a’,'em’,'b’)); | |
移除$source字符串内的a、em、b标签。
在php中模拟登陆一般会使用到curl来实现了,这个是php自带的一个函数了,我们可以简单的配置一下就能使用了,下面来看看吧。php模拟登陆的实现方法,这里分别列举两种方法实现模拟登陆人人网。具体实例代码如下:
1)使用snoopy模拟登陆
| 代码如下 | 复制代码 |
|
<?php | |
(2)使用curl模拟登陆
| 代码如下 | 复制代码 |
|
<?php $ch=curl_init(); | |
PHP计算相似度示例代码如下:
| 代码如下 | 复制代码 |
|
<?php |
|
例子出来了,估计大家还不知道算法,下面整理两篇文章供各位参考。
有一篇很长的文章,我要用计算机提取它的关键词(Automatic Keyphrase extraction),完全不加以人工干预,请问怎样才能正确做到?

让我们从一个实例开始讲起。假定现在有一篇长文《中国的蜜蜂养殖》,我们准备用计算机提取它的关键词。




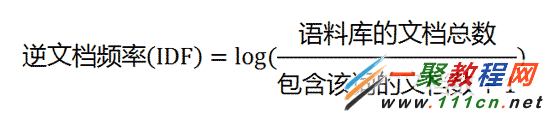
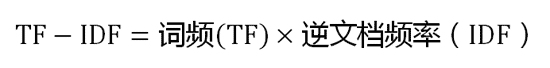
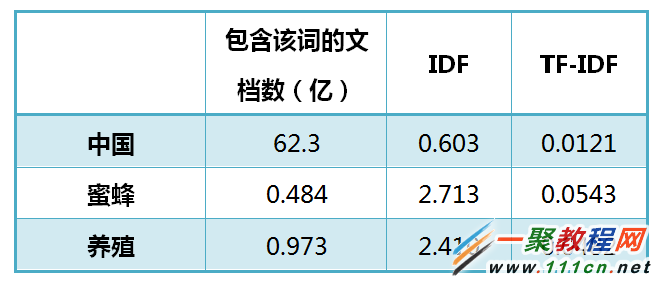
TF-IDF算法的优点是简单快速,结果比较符合实际情况。缺点是,单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。而且,这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的。(一种解决方法是,对全文的第一段和每一段的第一句话,给予较大的权重。)
为了简单起见,我们先从句子着手。
| 代码如下 | 复制代码 |
|
句子A:我喜欢看电视,不喜欢看电影。
句子B:我不喜欢看电视,也不喜欢看电影。
|
|
基本思路是:如果这两句话的用词越相似,它们的内容就应该越相似。因此,可以从词频入手,计算它们的相似程度。
第一步,分词。
| 代码如下 | 复制代码 |
|
句子A:我/喜欢/看/电视,不/喜欢/看/电影。
句子B:我/不/喜欢/看/电视,也/不/喜欢/看/电影。
|
|
| 代码如下 | 复制代码 |
|
我,喜欢,看,电视,电影,不,也。
|
|
| 代码如下 | 复制代码 |
|
句子A:我 1,喜欢 2,看 2,电视 1,电影 1,不 1,也 0。
句子B:我 1,喜欢 2,看 2,电视 1,电影 1,不 2,也 1。
|
|
| 代码如下 | 复制代码 |
|
句子A:[1, 2, 2, 1, 1, 1, 0]
句子B:[1, 2, 2, 1, 1, 2, 1]
|
|
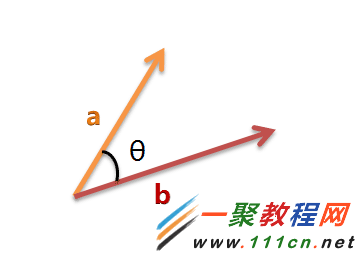
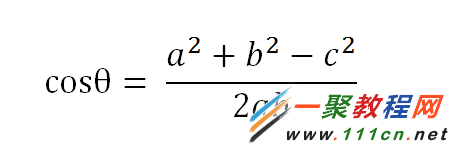
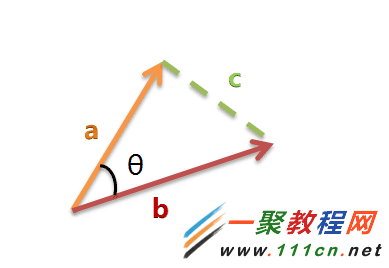
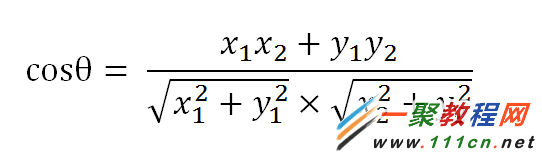
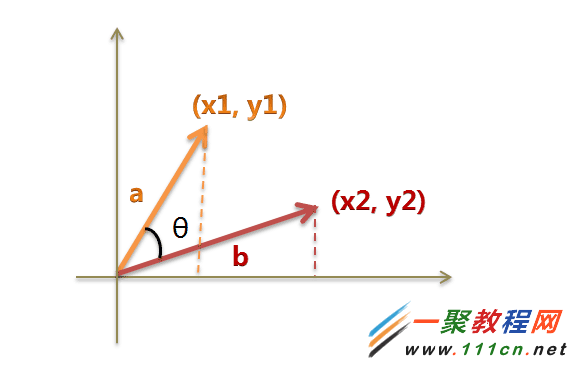
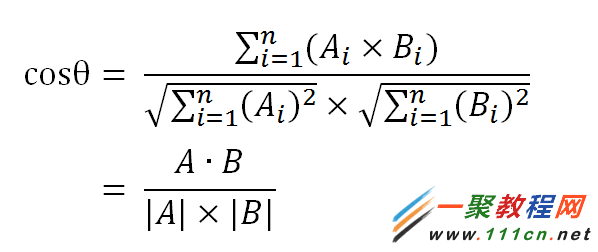
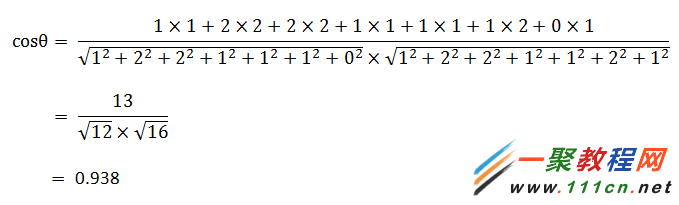
| 代码如下 | 复制代码 |
|
(1)使用TF-IDF算法,找出两篇文章的关键词;
(2)每篇文章各取出若干个关键词(比如20个),合并成一个集合,计算每篇文章对于这个集合中的词的词频(为了避免文章长度的差异,可以使用相对词频);
(3)生成两篇文章各自的词频向量;
(4)计算两个向量的余弦相似度,值越大就表示越相似。
|
|
相关文章
- eval函数在php中是一个函数并不是系统组件函数,我们在php.ini中的disable_functions是无法禁止它的,因这他不是一个php_function哦。 eval()针对php安全来说具有很...2016-11-25
- 在php中eval是一个函数并且不能直接禁用了,但eval函数又相当的危险了经常会出现一些问题了,今天我们就一起来看看eval函数对数组的操作 例子, <?php $data="array...2016-11-25
Python astype(np.float)函数使用方法解析
这篇文章主要介绍了Python astype(np.float)函数使用方法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下...2020-06-08- 这篇文章主要介绍了Python中的imread()函数用法说明,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-16
- 本文主要介绍了C# 中取绝对值的函数。具有很好的参考价值。下面跟着小编一起来看下吧...2020-06-25
- 下面小编就为大家带来一篇C#学习笔记- 随机函数Random()的用法详解。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧...2020-06-25
- 有一种方法,可以不打开网站而直接查看到这个网站的源代码.. 这样可以有效地防止误入恶意网站... 在浏览器地址栏输入: view-source:http://...2016-09-20
- <?php require('path.inc.php'); header('content-Type: text/html; charset=utf-8'); $borough_id = intval($_GET['id']); if(!$borough_id){ echo ' ...2016-11-25
- 本文实例讲述了JS基于Mootools实现的个性菜单效果代码。分享给大家供大家参考,具体如下:这里演示基于Mootools做的带动画的垂直型菜单,是一个初学者写的,用来学习Mootools的使用有帮助,下载时请注意要将外部引用的mootools...2015-10-23
- 本文实例讲述了JS+CSS实现分类动态选择及移动功能效果代码。分享给大家供大家参考,具体如下:这是一个类似选项卡功能的选择插件,与普通的TAb区别是加入了动画效果,多用于商品类网站,用作商品分类功能,不过其它网站也可以用,...2015-10-21
- 本文实例讲述了JS实现自定义简单网页软键盘效果。分享给大家供大家参考,具体如下:这是一款自定义的简单点的网页软键盘,没有使用任何控件,仅是为了练习JavaScript编写水平,安全性方面没有过多考虑,有顾虑的可以不用,目的是学...2015-11-08
- php 取除连续空格与换行代码,这些我们都用到str_replace与正则函数 第一种: $content=str_replace("n","",$content); echo $content; 第二种: $content=preg_replac...2016-11-25
- CREATE FUNCTION ChangeBigSmall (@ChangeMoney money) RETURNS VarChar(100) AS BEGIN Declare @String1 char(20) Declare @String2 char...2016-11-25
- php简单用户登陆程序代码 这些教程很对初学者来讲是很有用的哦,这款就下面这一点点代码了哦。 <center> <p> </p> <p> </p> <form name="form1...2016-11-25
- 这篇文章主要介绍了C++中Sort函数详细解析,sort函数是algorithm库下的一个函数,sort函数是不稳定的,即大小相同的元素在排序后相对顺序可能发生改变...2022-08-18
Android开发中findViewById()函数用法与简化
findViewById方法在android开发中是获取页面控件的值了,有没有发现我们一个页面控件多了会反复研究写findViewById呢,下面我们一起来看它的简化方法。 Android中Fin...2016-09-20- 公司一些wordpress网站由于下载的插件存在恶意代码,导致整个服务器所有网站PHP文件都存在恶意代码,就写了个简单的脚本清除。恶意代码示例...2015-10-23
- strstr() 函数搜索一个字符串在另一个字符串中的第一次出现。该函数返回字符串的其余部分(从匹配点)。如果未找到所搜索的字符串,则返回 false。语法:strstr(string,search)参数string,必需。规定被搜索的字符串。 参数sea...2013-10-04
- 本文实例讲述了JS实现双击屏幕滚动效果代码。分享给大家供大家参考,具体如下:这里演示双击滚屏效果代码的实现方法,不知道有觉得有用处的没,现在网上还有很多还在用这个特效的呢,代码分享给大家吧。运行效果截图如下:在线演...2015-10-30
- 其实挺简单的就是if(navigator.userAgent.indexOf('UCBrowser') > -1) {alert("uc浏览器");}else{//不是uc浏览器执行的操作}如果想测试某个浏览器的特征可以通过如下方法获取JS获取浏览器信息 浏览器代码名称:navigator...2015-11-08