php去除字符串中的HTML标签方法总结
先来看自己的写法
| 代码如下 | 复制代码 |
|
str_replace("<div class=\"summary-text\">",'',str_replace('</div>','',str_replace('</div>','',$vv))) | |
这个最简单就是替换$vv变量中指定的两个div了,后来发现有一个办法
| 代码如下 | 复制代码 |
|
$info = strip_tags($vv); | |
发现替换了所有html标签了,一面来看看strip_tags函数
trip_tags(string,allow):函数剥去 HTML、XML 以及 PHP 的标签。
| 代码如下 | 复制代码 |
|
$str = '郭碗瓢盆-<span style="color:#f00;">PHP</span>'; | |
由上面可以知道,在PHP中只能保留一些html标签,而不能指定删除一些html标签,于是我自己动手写一个放我平时的lib库文件中了。
| 代码如下 | 复制代码 |
|
| |
参数说明
$str — 是指需要过滤的一段字符串,比如div、p、em、img等html标签。
$tags — 是指想要移除指定的html标签,比如a、img、p等。
$stripContent = FALSE — 移除标签内的内容,比如将整个链接删除等,默认为False,即不删除标签内的内容。
使用说明
| 代码如下 | 复制代码 |
|
$target = strip_only_tags($source, array(‘a’,'em’,'b’)); | |
移除$source字符串内的a、em、b标签。
编程很多时候我们是拿来主意,不喜欢重复制造轮子,更何况php本身就是开源所以为了节约工作时间,平时就收集一些非常实用的php代码,现在我把它分享给大家,希望能够帮助php开发者提升工作效率。(建议学习还是自己多写代码)每位程序员和开发者都喜欢讨论他们最爱的代码片段,尤其是当PHP开发者花费数个小时为网页编码或创建应用时,他们更知道这些代码的重要性。为了节约编码时间,笔者收集了一些较为实用的代码片段,帮助开发者提高工作效率。>>>
1) Whois query using PHP ——利用PHP获取Whois请求
利用这段代码,在特定的域名里可获得whois信息。把域名名称作为参数,并显示所有域名的相关信息。
| 代码如下 | 复制代码 |
| function whois_query($domain) { // fix the domain name: $domain = strtolower(trim($domain)); $domain = preg_replace('/^http:///i', '', $domain); $domain = preg_replace('/^www./i', '', $domain); $domain = explode('/', $domain); $domain = trim($domain[0]); // split the TLD from domain name $_domain = explode('.', $domain); $lst = count($_domain)-1; $ext = $_domain[$lst]; // You find resources and lists // like these on wikipedia: // // <a href="http://de.wikipedia.org/wiki/Whois">http://de.wikipedia.org/wiki/Whois</a> // $servers = array( "biz" => "whois.neulevel.biz", "com" => "whois.internic.net", "us" => "whois.nic.us", "coop" => "whois.nic.coop", "info" => "whois.nic.info", "name" => "whois.nic.name", "net" => "whois.internic.net", "gov" => "whois.nic.gov", "edu" => "whois.internic.net", "mil" => "rs.internic.net", "int" => "whois.iana.org", "ac" => "whois.nic.ac", "ae" => "whois.uaenic.ae", "at" => "whois.ripe.net", "au" => "whois.aunic.net", "be" => "whois.dns.be", "bg" => "whois.ripe.net", "br" => "whois.registro.br", "bz" => "whois.belizenic.bz", "ca" => "whois.cira.ca", "cc" => "whois.nic.cc", "ch" => "whois.nic.ch", "cl" => "whois.nic.cl", "cn" => "whois.cnnic.net.cn", "cz" => "whois.nic.cz", "de" => "whois.nic.de", "fr" => "whois.nic.fr", "hu" => "whois.nic.hu", "ie" => "whois.domainregistry.ie", "il" => "whois.isoc.org.il", "in" => "whois.ncst.ernet.in", "ir" => "whois.nic.ir", "mc" => "whois.ripe.net", "to" => "whois.tonic.to", "tv" => "whois.tv", "ru" => "whois.ripn.net", "org" => "whois.pir.org", "aero" => "whois.information.aero", "nl" => "whois.domain-registry.nl" ); if (!isset($servers[$ext])){ die('Error: No matching nic server found!'); } $nic_server = $servers[$ext]; $output = ''; // connect to whois server: if ($conn = fsockopen ($nic_server, 43)) { fputs($conn, $domain."rn"); while(!feof($conn)) { $output .= fgets($conn,128); } fclose($conn); } else { die('Error: Could not connect to ' . $nic_server . '!'); } return $output; } |
|
2) Text messaging with PHP using the TextMagic API ——使用TextMagic API 获取PHP Test信息
TextMagic引入强大的核心API,可轻松将SMS发送到手机。该API是需要付费。
| 代码如下 | 复制代码 |
| the TextMagic PHP lib require('textmagic-sms-api-php/TextMagicAPI.php'); // Set the username and password information $username = 'myusername'; $password = 'mypassword'; // Create a new instance of TM $router = new TextMagicAPI(array( 'username' => $username, 'password' => $password )); // Send a text message to '999-123-4567' $result = $router->send('Wake up!', array(9991234567), true); // result: Result is: Array ( [messages] => Array ( [19896128] => 9991234567 ) [sent_text] => Wake up! [parts_count] => 1 ) |
|
3) Get info about your memory usage——获取内存使用率
这段代码帮助你获取内存使用率。
| 代码如下 | 复制代码 |
| echo "Initial: ".memory_get_usage()." bytes n"; /* prints Initial: 361400 bytes */ // let's use up some memory for ($i = 0; $i < 100000; $i++) { $array []= md5($i); } // let's remove half of the array for ($i = 0; $i < 100000; $i++) { unset($array[$i]); } echo "Final: ".memory_get_usage()." bytes n"; /* prints Final: 885912 bytes */ echo "Peak: ".memory_get_peak_usage()." bytes n"; /* prints Peak: 13687072 bytes */ |
|
4) Display source code of any webpage——查看任意网页源代码
如果你想查看网页源代码,那么只需更改第二行的URL,源代码就会在网页上显示出。
| 代码如下 | 复制代码 |
| <?php // display source code $lines = file('http://google.com/'); foreach ($lines as $line_num => $line) { // loop thru each line and prepend line numbers echo "Line #{$line_num} : " . htmlspecialchars($line) . " n"; } |
|
5) Create data uri’s——创建数据uri
通过使用此代码,你可以创建数据Uri,这对在HTML/CSS中嵌入图片非常有用,可帮助节省HTTP请求。
| 代码如下 | 复制代码 |
| function data_uri($file, $mime) { $contents=file_get_contents($file); $base64=base64_encode($contents); echo "data:$mime;base64,$base64"; } |
|
6) Detect location by IP——通过IP检索出地理位置
这段代码帮助你查找特定的IP,只需在功能参数上输入IP,就可检测出位置。
| 代码如下 | 复制代码 |
| function detect_city($ip) { $default = 'UNKNOWN'; if (!is_string($ip) || strlen($ip) < 1 || $ip == '127.0.0.1' || $ip == 'localhost') $ip = '8.8.8.8'; $curlopt_useragent = 'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.2) Gecko/20100115 Firefox/3.6 (.NET CLR 3.5.30729)'; $url = 'http://ipinfodb.com/ip_locator.php?ip=' . urlencode($ip); $ch = curl_init(); $curl_opt = array( CURLOPT_FOLLOWLOCATION => 1, CURLOPT_HEADER => 0, CURLOPT_RETURNTRANSFER => 1, CURLOPT_USERAGENT => $curlopt_useragent, CURLOPT_URL => $url, CURLOPT_TIMEOUT => 1, CURLOPT_REFERER => 'http://' . $_SERVER['HTTP_HOST'], ); curl_setopt_array($ch, $curl_opt); $content = curl_exec($ch); if (!is_null($curl_info)) { $curl_info = curl_getinfo($ch); } curl_close($ch); if ( preg_match('{ City : ([^<]*) }i’, $content, $regs) ) { $city = $regs[1]; } if ( preg_match(‘{ State/Province : ([^<]*) }i’, $content, $regs) ) { $state = $regs[1]; } if( $city!=” && $state!=” ){ $location = $city . ‘, ‘ . $state; return $location; }else{ return $default; } } |
|
7) Detect browser language——查看浏览器语言
检测浏览器使用的代码脚本语言。
| 代码如下 | 复制代码 |
| function get_client_language($availableLanguages, $default='en'){ if (isset($_SERVER['HTTP_ACCEPT_LANGUAGE'])) { $langs=explode(',',$_SERVER['HTTP_ACCEPT_LANGUAGE']); foreach ($langs as $value){ $choice=substr($value,0,2); if(in_array($choice, $availableLanguages)){ return $choice; } } } return $default; } |
|
8) Check if server is HTTPS——检测服务器是否是HTTPS
| 代码如下 | 复制代码 |
| if ($_SERVER['HTTPS'] != "on") { echo "This is not HTTPS"; }else{ echo "This is HTTPS"; } |
|
9) Generate CSV file from a PHP array——在PHP数组中生成.csv 文件
| 代码如下 | 复制代码 |
| function generateCsv($data, $delimiter = ',', $enclosure = '"') { $handle = fopen('php://temp', 'r+'); foreach ($data as $line) { fputcsv($handle, $line, $delimiter, $enclosure); } rewind($handle); while (!feof($handle)) { $contents .= fread($handle, 8192); } fclose($handle); return $contents; } |
|
一、查看邮件是否已被阅读
当你在发送邮件时,你或许很想知道该邮件是否被对方已阅读。这里有段非常有趣的代码片段能够显示对方IP地址记录阅读的实际日期和时间。
| 代码如下 | 复制代码 |
<? |
|
二、从网页中提取关键字
一段伟大的代码片段能够轻松的从网页中提取关键字。
| 代码如下 | 复制代码 |
$meta = get_meta_tags('http://www.emoticode.net/');
|
|
三、查找页面上的所有链接
使用DOM,你可以轻松从任何页面上抓取链接,代码示例如下:
| 代码如下 | 复制代码 |
$html = file_get_contents('http://www.php100.com');
|
|
四、自动转换URL,跳转至超链接
在WordPress中,如果你想自动转换URL,跳转至超链接页面,你可以利用内置的函数make_clickable()执行此操作。如果你想基于WordPress之外操作该程序,那么你可以参考wp-includes/formatting.php源代码。
| 代码如下 | 复制代码 |
function _make_url_clickable_cb($matches) {
|
|
五、创建数据URL
数据URL可以直接嵌入到HTML/CSS/JS中,以节省大量的 HTTP请求。 下面的这段代码可利用$file轻松创建数据URL。
| 代码如下 | 复制代码 |
function data_uri($file, $mime) {
|
|
六、从服务器上下载&保存一个远程图片
当你在搭建网站时,从远程服务器下载某张图片并且将其保存在自己的服务器上,这一操作会经常用到。代码如下:
| 代码如下 | 复制代码 |
$image = file_get_contents('http://www.php100.com/image.jpg');
|
|
七、移除Remove Microsoft Word HTML Tag
当你使用Microsoft Word会创建许多Tag,比如font,span,style,class等。这些标签对于Word本身而言是非常有用的,但是当你从Word粘贴至网页时,你会发现很多无用的Tag。因此,下面的这段代码可帮助你删除所有无用的Word HTML Tag。
| 代码如下 | 复制代码 |
function cleanHTML($html) {
|
|
八、检测浏览器语言
如果你的网站上有多种语言,那么可以使用这段代码作为默认的语言来检测浏览器语言。该段代码将返回浏览器客户端使用的初始语言。
| 代码如下 | 复制代码 |
function get_client_language($availableLanguages, $default='en'){
|
|
九、显示Facebook 粉丝数量
如果你的网站或者博客上有内链的Facebook页面,你或许想知道拥有多少粉丝。这段代码将帮助你查看Facebook粉丝数,记住,别忘了在你的页面ID第二行添加该段代码。
| 代码如下 | 复制代码 |
<?php |
|
php模拟登陆的实现方法,这里分别列举两种方法实现模拟登陆人人网。具体实例代码如下:
1)使用snoopy模拟登陆
| 代码如下 | 复制代码 |
|
<?php | |
(2)使用curl模拟登陆
| 代码如下 | 复制代码 |
|
<?php $ch=curl_init(); | |
PHP计算相似度示例代码如下:
| 代码如下 | 复制代码 |
|
<?php |
|
例子出来了,估计大家还不知道算法,下面整理两篇文章供各位参考。
有一篇很长的文章,我要用计算机提取它的关键词(Automatic Keyphrase extraction),完全不加以人工干预,请问怎样才能正确做到?

让我们从一个实例开始讲起。假定现在有一篇长文《中国的蜜蜂养殖》,我们准备用计算机提取它的关键词。




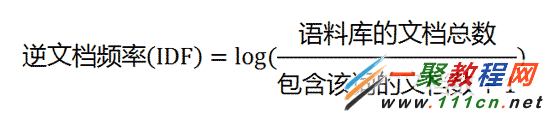
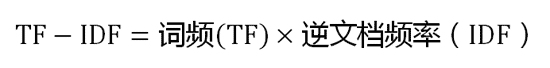
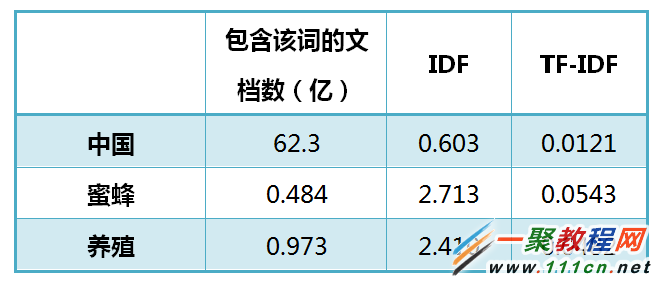
TF-IDF算法的优点是简单快速,结果比较符合实际情况。缺点是,单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。而且,这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的。(一种解决方法是,对全文的第一段和每一段的第一句话,给予较大的权重。)
为了简单起见,我们先从句子着手。
| 代码如下 | 复制代码 |
|
句子A:我喜欢看电视,不喜欢看电影。
句子B:我不喜欢看电视,也不喜欢看电影。
|
|
基本思路是:如果这两句话的用词越相似,它们的内容就应该越相似。因此,可以从词频入手,计算它们的相似程度。
第一步,分词。
| 代码如下 | 复制代码 |
|
句子A:我/喜欢/看/电视,不/喜欢/看/电影。
句子B:我/不/喜欢/看/电视,也/不/喜欢/看/电影。
|
|
| 代码如下 | 复制代码 |
|
我,喜欢,看,电视,电影,不,也。
|
|
| 代码如下 | 复制代码 |
|
句子A:我 1,喜欢 2,看 2,电视 1,电影 1,不 1,也 0。
句子B:我 1,喜欢 2,看 2,电视 1,电影 1,不 2,也 1。
|
|
| 代码如下 | 复制代码 |
|
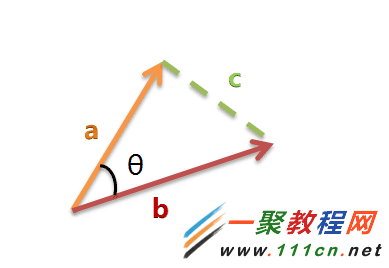
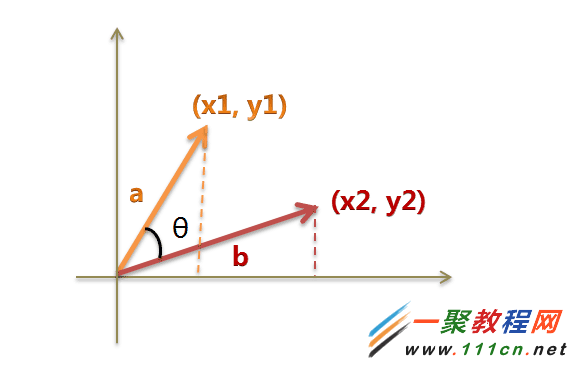
句子A:[1, 2, 2, 1, 1, 1, 0]
句子B:[1, 2, 2, 1, 1, 2, 1]
|
|
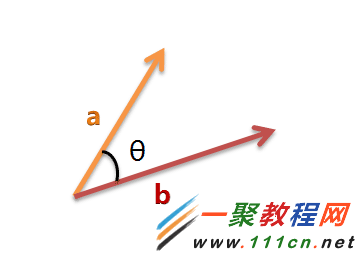
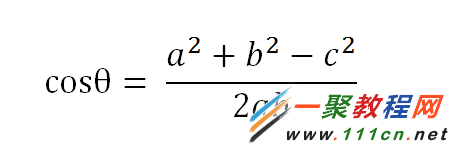
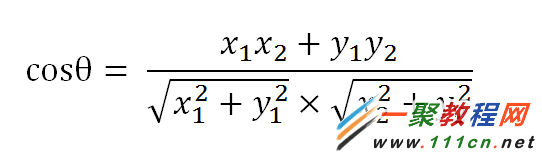
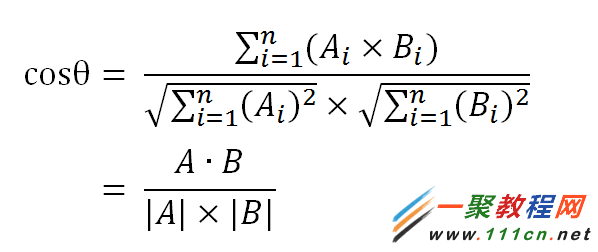
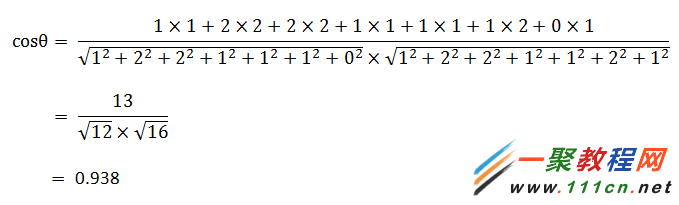
| 代码如下 | 复制代码 |
|
(1)使用TF-IDF算法,找出两篇文章的关键词;
(2)每篇文章各取出若干个关键词(比如20个),合并成一个集合,计算每篇文章对于这个集合中的词的词频(为了避免文章长度的差异,可以使用相对词频);
(3)生成两篇文章各自的词频向量;
(4)计算两个向量的余弦相似度,值越大就表示越相似。
|
|
PHP这门程序设计语言简单得令人发指,那是因为PHP的作者们太神通。今天我来谈谈所有的phper都熟悉的session(会话)。
需要说明的是:
4./session/indexFile和/session/indexRedis模板中两个ajax请求,/session/setUserFile和/session/setUserRedis立即执行,/session/setLoginFile和/session/setLoginRedis延迟300ms,是为了模拟同一个用户,同时在两个页面(请求)修改会话数据
执行结果表象:
第一次访问:

第二次访问:

请求:/session/indexredis
第一次访问:

第二次访问:

手册中有这样的描述:
void session_write_close ( void )
Session data is usually stored after your script terminated without the need to call session_write_close(), but as session data is locked to prevent concurrent writes only one script may operate on a session at any time. When using framesets together with sessions you will experience the frames loading one by one due to this locking. You can reduce the time needed to load all the frames by ending the session as soon as all changes to session variables are done.
也就是说session是有锁的,为防止并发的写会话数据。php自带的的文件保存会话数据是加了一个互斥锁(session_start()的时候),从而解释了上面呈现的两个请求响应时间相同。但是以redis保存会话数据时,第二个ajax虽然没有阻塞,但是会话数据并没有写入到redis,那我们追溯一下源码就有答案了。

| 代码如下 | 复制代码 |
<?php
final class SessionController extends YafController_Abstract
{
public function setUserFileAction()
{
session_start();
$_SESSION['user_name'] = 'xudianyang';
$_SESSION['user_id'] = '123';
sleep(3);
echo json_encode($_SESSION);
return false;
}
public function setLoginFileAction()
{
session_start();
$_SESSION['last_time'] = time();
echo json_encode($_SESSION);
return false;
}
public function indexFileAction()
{
// Auto Rend View
}
public function getSessionFileAction()
{
session_start();
var_dump($_SESSION);
return false;
}
public function setUserRedisAction()
{
$session = CoreFactory::session();
$session->set('user_name', 'xudianyang');
$session->set('user_id', '123');
sleep(3);
echo json_encode($_SESSION);
return false;
}
public function setLoginRedisAction()
{
$session = CoreFactory::session();
$session->set('last_time', time());
echo json_encode($_SESSION);
return false;
}
public function indexRedisAction()
{
// Auto Rend View
}
public function getSessionRedisAction()
{
$session = CoreFactory::session();
var_dump($_SESSION);
return false;
}
}
indexfile.phtml
<!DOCTYPE html>
<html>
<head>
<title>测试session并发锁问题</title>
<meta charset="utf-8">
<script type="text/javascript" src="/assets/js/jquery-1.10.2.min.js"></script>
<script type="text/javascript">
$.ajax({
url: "/session/setUserFile",
type: "get",
dataType: "json",
success: function(response){
console.info(response.last_time);
}
});
setTimeout(function(){
$.ajax({
url: "/session/setLoginFile",
type: "get",
dataType: "json",
success: function(response){
console.info(response.last_time);
}
});
}, 300);
</script>
</head>
<body>
同时发起2两个ajax请求
</body>
</html>
indexredis.phtml
<!DOCTYPE html>
<html>
<head>
<title>测试session并发锁问题</title>
<meta charset="utf-8">
<script type="text/javascript" src="/assets/js/jquery-1.10.2.min.js"></script>
<script type="text/javascript">
$.ajax({
url: "/session/setUserRedis",
type: "get",
dataType: "json",
success: function(response){
console.info(response.last_time);
}
});
setTimeout(function(){
$.ajax({
url: "/session/setLoginRedis",
type: "get",
dataType: "json",
success: function(response){
console.info(response.last_time);
}
});
}, 300);
</script>
</head>
<body>
同时发起2两个ajax请求
</body>
</html>
| |
相关文章
- 这篇文章主要介绍了C#中截取字符串的的基本方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-11-03
- 这篇文章介绍了C#判断字符串是否数字或字母的实例,有需要的朋友可以参考一下...2020-06-25
- 这篇文章主要介绍了PostgreSQL判断字符串是否包含目标字符串的多种方法,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下...2021-02-23
- 这篇文章主要介绍了C++ string常用截取字符串方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-04-25
- 本文实例讲述了php字符串按照单词进行反转的方法。分享给大家供大家参考。具体分析如下:下面的php代码可以将字符串按照单词进行反转输出,实际上是现将字符串按照空格分隔到数组,然后对数组进行反转输出。...2015-03-15
- 这篇文章主要介绍了使用list stream:任意对象List拼接字符串操作,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教...2021-09-09
- 这篇文章主要介绍了MySQL 字符串拆分操作(含分隔符的字符串截取),具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-02-22
- 1、先讲讲JQuery的概念,JQuery首先是由一个 America 的叫什么 John Resig的人创建的,后来又很多的JS高手也加入了这个团队。其实 JQuery是一个JavaScript的类库,这个类库集合了很多功能方法,利用类库你可以用简单的一些代...2014-05-31
- 这篇文章主要介绍了C# 16 进制字符串转 int的方法,非常不错,具有参考借鉴价值,需要的朋友可以参考下...2020-06-25
- JS中默认中文字符长度和其它字符长度计算方法是一样的,但某些情况下我们需要获取中文字符串的实际长度,代码如下: 复制代码 代码如下: function strLength(str) { var realLength = 0, len = str.length, charCode = -1;...2014-06-07
- 这篇文章主要介绍了C#实现字符串转换成字节数组的简单实现方法,仅一行代码即可搞定,非常简单实用,需要的朋友可以参考下...2020-06-25
- 文章介绍一个实用的函数,我们如果用php substr来截取字符在中文上处理的很有问题,今天自己写了一个比较好的中文与英文字符截取的函数,有需要的朋友可以参考下。 ...2016-11-25
- 这篇文章主要介绍了C#实现对字符串进行大小写切换的方法,涉及C#操作字符串的技巧,具有一定参考借鉴价值,需要的朋友可以参考下...2020-06-25
- 这篇文章主要介绍了c#将字节数组转成易读的字符串的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-06-25
- 这篇文章主要介绍了PostgreSQL 字符串处理与日期处理操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-02-01
- 这篇文章主要介绍了C#获取字符串后几位数的方法,实例分析了C#操作字符串的技巧,具有一定参考借鉴价值,需要的朋友可以参考下...2020-06-25
- 这篇文章主要介绍了C#判断一个字符串是否是数字或者含有某个数字的方法,本文给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下...2020-06-25
- 这篇文章主要介绍了Substring截取字符串方法小结,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-06-25
- 在网站开发中,我们经常使用php similar text 计算两个字符串相似度;1,similar_text的用法 如果我想计算"ly89cn"和"ly89"的相似程度,有两种表示方法复制代码 代码如下: echo similar_text('ly89cn', 'ly89'); ...2015-11-08
- 这篇文章主要介绍了C#实现将字符串转换成日期格式的方法,涉及C#操作时间及字符串的相关技巧,非常简单实用,需要的朋友可以参考下...2020-06-25