数据源架构模式 表入口 行入口 活动记录 数据映射器
数据源架构模式 - 表入口模式
表入口模式充当数据库表访问入口的对象,一个实例处理表中的所有行。
可以理解为对之前分散在各个页面的sql语句进行封装,一张表就是一个对象,该对象处理所有与该表有关的业务逻辑,很好的提高了代码的复用性。
现在想起来,当初刚毕业那会儿,经常使用表入口模式。
具体的实现方式参见代码:
database.php
<?php
class Database{
//只是为了演示,通常情况下数据库的配置是会单独写在配置文件中的
private static $_dbConfig = array(
'host' => '127.0.0.1',
'username' => 'root',
'pwd' => '',
'dbname' => 'bussiness'
);
private static $_instance;
public static function getInstance(){
if(is_null(self::$_instance)){
self::$_instance = new mysqli(self::$_dbConfig['host'], self::$_dbConfig['username'], self::$_dbConfig['pwd'], self::$_dbConfig['dbname']);
if(self::$_instance->connect_errno){
throw new Exception(self::$_instance->connect_error);
}
}
return self::$_instance;
}
}
person.php
<?php
require_once 'database.php';
class Person extends Database{
public $instance;
public $table = 'person';
public function __construct(){
$this->instance = Person::getInstance();
}
public function getPersonById($personId){
$sql = "select * from $this->table where id=$personId";
echo $sql;
return $this->instance->query($sql);
}
/**其他的一些增删改查操作方法...**/
}
index.php
<?php require_once 'person.php'; $person = new Person(); var_dump($person->getPersonById(1)->fetch_assoc()); die();
运行结果:
select * from person where id=1
array (size=2)
'id' => string '1' (length=1)
'name' => string 'ben' (length=3)
数据源架构模式 - 行入口模式
一、概念
行数据入口(Row Data Gateway):充当数据源中单条记录入口的对象,每行一个实例。
二、简单实现行数据入口
为了方便理解,还是先简单实现:
<?php
/**
* 企业应用架构 数据源架构模式之行数据入口 2010-09-27 sz
* @author phppan.p#gmail.com http://www.phppan.com
* 哥学社成员(http://www.blog-brother.com/)
* @package architecture
*/
class PersonGateway {
private $_name;
private $_id;
private $_birthday;
public function __construct($id, $name, $birthday) {
$this->setId($id);
$this->setName($name);
$this->setBirthday($birthday);
}
public function getName() {
return $this->_name;
}
public function setName($name) {
$this->_name = $name;
}
public function getId() {
return $this->_id;
}
public function setId($id) {
$this->_id = $id;
}
public function getBirthday() {
return $this->_birthday;
}
public function setBirthday($birthday) {
$this->_birthday = $birthday;
}
/**
* 入口类自身拥有更新操作
*/
public function update() {
$data = array('id' => $this->_id, 'name' => $this->_name, 'birthday' => $this->_birthday);
$sql = "UPDATE person SET ";
foreach ($data as $field => $value) {
$sql .= "`" . $field . "` = '" . $value . "',";
}
$sql = substr($sql, 0, -1);
$sql .= " WHERE id = " . $this->_id;
return DB::query($sql);
}
/**
* 入口类自身拥有插入操作
*/
public function insert() {
$data = array('name' => $this->_name, 'birthday' => $this->_birthday);
$sql = "INSERT INTO person ";
$sql .= "(`" . implode("`,`", array_keys($data)) . "`)";
$sql .= " VALUES('" . implode("','", array_values($data)) . "')";
return DB::query($sql);
}
public static function load($rs) {
/* 此处可加上缓存 */
return new PersonGateway($rs['id'] ? $rs['id'] : NULL, $rs['name'], $rs['birthday']);
}
}
/**
* 人员查找类
*/
class PersonFinder {
public function find($id) {
$sql = "SELECT * FROM person WHERE id = " . $id;
$rs = DB::query($sql);
return PersonGateway::load($rs);
}
public function findAll() {
$sql = "SELECT * FROM person";
$rs = DB::query($sql);
$result = array();
if (is_array($rs)) {
foreach ($rs as $row) {
$result[] = PersonGateway::load($row);
}
}
return $result;
}
}
class DB {
/**
* 这只是一个执行SQL的演示方法
* @param string $sql 需要执行的SQL
*/
public static function query($sql) {
echo "执行SQL: ", $sql, " <br />";
if (strpos($sql, 'SELECT') !== FALSE) { // 示例,对于select查询返回查询结果
return array('id' => 1, 'name' => 'Martin', 'birthday' => '2010-09-15');
}
}
}
/**
* 客户端调用
*/
class Client {
/**
* Main program.
*/
public static function main() {
header("Content-type:text/html; charset=utf-8");
/* 写入示例 */
$data = array('name' => 'Martin', 'birthday' => '2010-09-15');
$person = PersonGateway::load($data);
$person->insert();
/* 更新示例 */
$data = array('id' => 1, 'name' => 'Martin', 'birthday' => '2010-09-15');
$person = PersonGateway::load($data);
$person->setName('Phppan');
$person->update();
/* 查询示例 */
$finder = new PersonFinder();
$person = $finder->find(1);
echo $person->getName();
}
}
Client::main();
?>三、运行机制
●行数据入口是单条记录极其相似的对象,在该对象中数据库中的每一列为一个域。
●行数据入口一般能实现从数据源类型到内存中类型的任意转换。
●行数据入口不存在任何领域逻辑,如果存在,则是活动记录。
●在实例可看到,为了从数据库中读取信息,设置独立的OrderFinder类。当然这里也可以选择不新建类,采用静态查找方法,但是它不支持需要为不同数据源提供不同查找方法的多态。因此这里最好单独设置查找方法的对象。
●行数据入口除了可以用于表外还可以用于视图。需要注意的是视图的更新操作。
●在代码中可见“定义元数据映射”,这是一种很好的作法,这样一来,所有的数据库访问代码都可以在自动建立过程中自动生成。
四、使用场景
4.1 事务脚本
可以很好地分离数据库访问代码,并且也很容易被不同的事务脚本重用。不过可能会发现业务逻辑在多处脚本中重复出现,这些逻辑可能在行数据入口中有用。不断移动这些逻辑会使行数据入口演变为活动记录,这样减少了业务逻辑的重复。
4.2 领域模型
如果要改变数据库的结构但不想改变领域逻辑,采用行数据入口是不错的选择。大多数情况,数据映射器更加适合领域模型。
行数据入口能和数据映射器一起配合使用,尽管这样看起来有点多此一举,不过,当行数据入口从元数据自动生成,而数据映射器由手动实现时,这种方法会很有效。
数据源架构模式 - 活动记录
【活动记录的意图】
一个对象,它包装数据表或视图中某一行,封装数据库访问,并在这些数据上增加了领域逻辑。
【活动记录的适用场景】
适用于不太复杂的领域逻辑,如CRUD操作等。
【活动记录的运行机制】
对象既有数据又有行为。其使用最直接的方法,将数据访问逻辑置于领域对象中。
活动记录的本质是一个领域模型,这个领域模型中的类和基数据库中的记录结构应该完全匹配,类的每个域对应表的每一列。
一般来说,活动记录包括如下一些方法:
1、由数据行构造一个活动记录实例;
2、为将来对表的插入构造一个新的实例;
3、用静态查找方法来包装常用的SQL查询和返回活动记录;
4、更新数据库并将活动记录中的数据插入数据库;
5、获取或设置域;
6、实现部分业务逻辑。
【活动记录的优点和缺点】
优点:
1、简单,容易创建并且容易理解。
2、在使用事务脚本时,减少代码复制。
3、可以在改变数据库结构时不改变领域逻辑。
4、基于单个活动记录的派生和测试验证会很有效。
缺点:
1、没有隐藏关系数据库的存在。
2、仅当活动记录对象和数据库中表直接对应时,活动记录才会有效。
3、要求对象的设计和数据库的设计紧耦合,这使得项目中的进一步重构很困难
【活动记录与其它模式】
数据源架构模式之行数据入口:活动记录与行数据入口十分类似。二者的主要差别是行数据入口 仅有数据库访问而活动记录既有数据源逻辑又有领域逻辑。
【活动记录的PHP示例】
<?php
/**
* 企业应用架构 数据源架构模式之活动记录 2010-10-17 sz
* @author phppan.p#gmail.com http://www.phppan.com
* 哥学社成员(http://www.blog-brother.com/)
* @package architecture
*/
/**
* 定单类
*/
class Order {
/**
* 定单ID
* @var <type>
*/
private $_order_id;
/**
* 客户ID
* @var <type>
*/
private $_customer_id;
/**
* 定单金额
* @var <type>
*/
private $_amount;
public function __construct($order_id, $customer_id, $amount) {
$this->_order_id = $order_id;
$this->_customer_id = $customer_id;
$this->_amount = $amount;
}
/**
* 实例的删除操作
*/
public function delete() {
$sql = "DELETE FROM Order SET WHERE order_id = " . $this->_order_id . " AND customer_id = " . $this->_customer_id;
return DB::query($sql);
}
/**
* 实例的更新操作
*/
public function update() {
}
/**
* 插入操作
*/
public function insert() {
}
public static function load($rs) {
return new Order($rs['order_id'] ? $rs['order_id'] : NULL, $rs['customer_id'], $rs['amount'] ? $rs['amount'] : 0);
}
}
class Customer {
private $_name;
private $_customer_id;
public function __construct($customer_id, $name) {
$this->_customer_id = $customer_id;
$this->_name = $name;
}
/**
* 用户删除定单操作 此实例方法包含了业务逻辑
* 通过调用定单实例实现
* 假设此处是对应的删除操作(实际中可能是一种以某字段来标记的假删除操作)
*/
public function deleteOrder($order_id) {
$order = Order::load(array('order_id' => $order_id, 'customer_id' => $this->_customer_id));
return $order->delete();
}
/**
* 实例的更新操作
*/
public function update() {
}
/**
* 入口类自身拥有插入操作
*/
public function insert() {
}
public static function load($rs) {
/* 此处可加上缓存 */
return new Customer($rs['customer_id'] ? $rs['customer_id'] : NULL, $rs['name']);
}
/**
* 根据客户ID 查找
* @param integer $id 客户ID
* @return Customer 客户对象
*/
public static function find($id) {
return CustomerFinder::find($id);
}
}
/**
* 人员查找类
*/
class CustomerFinder {
public static function find($id) {
$sql = "SELECT * FROM person WHERE customer_id = " . $id;
$rs = DB::query($sql);
return Customer::load($rs);
}
}
class DB {
/**
* 这只是一个执行SQL的演示方法
* @param string $sql 需要执行的SQL
*/
public static function query($sql) {
echo "执行SQL: ", $sql, " <br />";
if (strpos($sql, 'SELECT') !== FALSE) { // 示例,对于select查询返回查询结果
return array('customer_id' => 1, 'name' => 'Martin');
}
}
}
/**
* 客户端调用
*/
class Client {
/**
* Main program.
*/
public static function main() {
header("Content-type:text/html; charset=utf-8");
/* 加载客户ID为1的客户信息 */
$customer = Customer::find(1);
/* 假设用户拥有的定单id为 9527*/
$customer->deleteOrder(9527);
}
}
Client::main();
?>
同前面的文章一样,这仅仅是一个活动记录的示例,关于活动记录模式的应用,可以查看Yii框架中的DB类,在其源码中有一个CActiveRecord抽象类,从这里可以看到活动记录模式的应用
另外,如果从事务脚本中创建活动记录,一般是首先将表包装为入口,接着开始行为迁移,使表深化成为活动记录。
对于活动记录中的域的访问和设置可以如yii框架一样,使用魔术方法__set方法和__get方法。
数据源架构模式 - 数据映射器
一:数据映射器
关系型数据库用来存储数据和关系,对象则可以处理业务逻辑,所以,要把数据本身和业务逻辑糅杂到一个对象中,我们要么使用 活动记录,要么把两者分开,通过数据映射器把两者关联起来。
数据映射器是分离内存对象和数据库的中间软件层,下面这个时序图描述了这个中间软件层的概念:
在这个时序图中,我们还看到一个概念,映射器需能够获取领域对象(在这个例子中,a Person 就是一个领域对象)。而对于数据的变化(或者说领域对象的变化),映射器还必须要知道这些变化,在这个时候,我们就需要 工作单元 模式(后议)。
从上图中,我们仿佛看到 数据映射器 还蛮简单的,复杂的部分是:我们需要处理联表查询,领域对象的继承等。领域对象的字段则可能来自于数据库中的多个表,这种时候,我们就必须要让数据映射器做更多的事情。是的,以上我们说到了,数据映射器要能做到两个复杂的部分:
1:感知变化;
2:通过联表查询的结果,为领域对象赋值;
为了感知变化以及与数据库对象保持一致,则需要 标识映射(架构模式对象与关系结构模式之:标识域(Identity Field)),这通常需要有 标识映射的注册表,或者为每个查找方法持有一个 标识映射,下面的代码是后者:
void Main()
{
SqlHelper.ConnectionString = "Data Source=xxx;Initial Catalog=xxx;Integrated Security=False;User ID=sa;Password=xxx;Connect Timeout=15;Encrypt=False;TrustServerCertificate=False";
var user1 = User.FindUser("6f7ff44435f3412cada61898bcf0df6c");
var user2 = User.FindUser("6f7ff44435f3412cada61898bcf0df6c");
(user1 == user2).Dump();
"END".Dump();
}
public abstract class BaseMode
{
public string Id {get; set;}
public string Name {get; set;}
}
public class User : BaseMode
{
static UserMap map = new UserMap();
public static User FindUser(string id)
{
var user = map.Find(id);
return user;
}
}
public class UserMap : AbstractMapper<User>
{
public User Find(string id)
{
return (User)AbstractFind(id);
}
protected override User AbstractFind(string id)
{
var user = base.AbstractFind(id);
if( user == null )
{
"is Null".Dump();
string sql = "SELECT * FROM [EL_Organization].[User] WHERE ID=@Id";
var pms = new SqlParameter[]
{
new SqlParameter("@Id", id)
};
var ds = SqlHelper.ExecuteDataset(CommandType.Text, sql, pms);
user = DataTableHelper.ToList<User>(ds.Tables[0]).FirstOrDefault();
if(user == null)
{
return null;
}
user = Load(user);
return user;
}
return user;
}
public List<User> FindList(string name)
{
// SELECT * FROM USER WHERE NAME LIKE NAME
List<User> users = null;
return LoadAll(users);
}
public void Update(User user)
{
// UPDATE USER SET ....
}
}
public abstract class AbstractMapper<T> where T : BaseMode
{
// 这里的问题是,随着对象消失,loadedMap就被回收
protected Dictionary<string, T> loadedMap = new Dictionary<string, T>();
protected T Load(T t)
{
if(loadedMap.ContainsKey(t.Id) )
{
return loadedMap[t.Id];
}
else
{
loadedMap.Add(t.Id, t);
return t;
}
}
protected List<T> LoadAll(List<T> ts)
{
for(int i=0; i < ts.Count; i++)
{
ts[i] = Load(ts[i]);
}
return ts;
}
protected virtual T AbstractFind(string id)
{
if(loadedMap.ContainsKey(id))
{
return loadedMap[id];
}
else
{
return null;
}
}
}
上面是一个简单的映射器,它具备了 标识映射 功能。由于有标识映射,所以我们运行这段代码得到的结果是: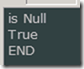
回归本问实质,问题:什么叫 “数据映射”
其实,这个问题很关键,
UserMap 通过 Find 方法,将数据库记录变成了一个 User 对象,这就叫 “数据映射”,但是,真正起到核心作用的是 user = DataTableHelper.ToList<User>(ds.Tables[0]).FirstOrDefault(); 这行代码。更进一步的,DataTableHelper.ToList<T> 这个方法完成了 数据映射 功能。
那么,DataTableHelper.ToList<T> 方法具体干了什么事情,实际上,无非就是根据属性名去获取 DataTable 的字段值。这是一种简便的方法,或者说,在很多业务不复杂的场景下,这也许是个好办法,但是,因为业务往往是复杂的,所以实际情况下,我们使用这个方法的情况并不是很多,大多数情况下,我们需要像这样编码来完成映射:
someone.Name = Convert.ToString(row["Name"])
不要怀疑,上面这行代码,就叫数据映射,任何高大上的概念,实际上就是那条你写了很多遍的代码。
1.1 EntityFramework 中的数据映射
这是一个典型的 EF 的数据映射类,
public class CourseMap : EntityTypeConfiguration<Course>
{
public CourseMap()
{
// Primary Key
this.HasKey(t => t.CourseID);
// Properties
this.Property(t => t.CourseID)
.HasDatabaseGeneratedOption(DatabaseGeneratedOption.None);
this.Property(t => t.Title)
.IsRequired()
.HasMaxLength(100);
// Table & Column Mappings
this.ToTable("Course");
this.Property(t => t.CourseID).HasColumnName("CourseID");
this.Property(t => t.Title).HasColumnName("Title");
this.Property(t => t.Credits).HasColumnName("Credits");
this.Property(t => t.DepartmentID).HasColumnName("DepartmentID");
// Relationships
this.HasMany(t => t.People)
.WithMany(t => t.Courses)
.Map(m =>
{
m.ToTable("CourseInstructor");
m.MapLeftKey("CourseID");
m.MapRightKey("PersonID");
});
this.HasRequired(t => t.Department)
.WithMany(t => t.Courses)
.HasForeignKey(d => d.DepartmentID);
}
}
我们可以看到,EF 的数据映射,那算是真正的数据映射。最基本的,其在内部无非是干了一件这样的事情:
数据库是哪个字段,对应的内存对象的属性是哪个属性。
最终,它都是通过一个对象工厂把领域模型生成出来,其原理大致如下:
internal static Course BuildCourse(IDataReader reader)
{
Course course = new Course(reader[FieldNames.CourseId]);
contract.Title = reader[FieldNames.Title].ToString();
…
return contract;
}
二:仓储库
UserMap 关于 数据映射器 的概念是不是觉得太重了?因为它干了 映射 和 持久化 的事情,它甚至还得持有 工作单元。那么,如果我们能不能像 EF 一样,映射器 只干映射的事情,而把其余事情分出去呢?可以,分离出去的这部分就叫做 仓储库。
三:再多说一点 DataTableHelper.ToList<T>,简化的数据映射器
其实就是 DataTable To List 了。如果你在用 EF 或者 NHibernate 这样的框架,那么,就用它们提供的映射器好了(严格来说,你不是在使用它们的映射器。因为这些框架本身才是在使用自己的映射器,我们只是在配置映射器所要的数据和关系而已,有时候,这些配置是在配置文件中,有时候是在字段或属性上加 Attribute,有时候则是简单但庞大的单行代码)。我们当然也可以创建自己的 标准的 映射器,Tim McCarthy 在 《领域驱动设计 C# 2008 实现》 中就实现了这样的映射器。但是,EF 和 NHibernate 固然很好,但是很多时候我们还是不得不使用 手写SQL,因为:
1:EF 和 NHibernate 是需要学习成本的,这代表者团队培训成本高,且易出错的;
2:不应放弃 手写SQL 的高效性。
Session 和 Cookie 有什么关系
Cookie 也是由于 HTTP 无状态的特点而产生的技术。也被用于保存访问者的身份标识和一些数据。每次客户端发起 HTTP 请求时,会将 Cookie 数据加到 HTTP header 中,提交给服务端。这样服务端就可以根据 Cookie 的内容知道访问者的信息了。
可以说,Session 和 Cookie 做着相似的事情,只是 Session 是将数据保存在服务端,通过客户端提交来的 session_id 来获取对应的数据;而 Cookie 是将数据保存在客户端,每次发起请求时将数据提交给服务端的。
上面提到,session_id 可以通过 URL 或 cookie 来传递,由于 URL 的方式比 cookie 的方式更加不安全且使用不方便,所以一般是采用 cookie 来传递 session_id。
服务端生成 session_id,通过 HTTP 报文发送给客户端(比如浏览器),客户端收到后按指示创建保存着 session_id 的 cookie。cookie 是以 key/value 形式保存的,看上去大概就这个样子的:
PHPSESSID=e4tqo2ajfbqqia9prm8t83b1f2
在 PHP 中,保存 session_id 的 cookie 名称默认叫作 PHPSESSID,这个名称可以通过 php.ini 中 session.name 来修改,也可以通过函数 session_name() 来修改。
为什么不推荐使用 PHP 自带的 files 型 Session 处理器
在 PHP 中,默认的 Session 处理器是 files,处理器可以用户自己实现(参见:自定义会话管理器)。我知道的成熟的 Session 处理器还有很多:Redis、Memcached、MongoDB……为什么不推荐使用 PHP 自带的 files 类型处理器,PHP 官方手册中给出过这样一段 Note:
无论是通过调用函数 session_start() 手动开启会话, 还是使用配置项 session.auto_start 自动开启会话, 对于基于文件的会话数据保存(PHP 的默认行为)而言, 在会话开始的时候都会给会话数据文件加锁, 直到 PHP 脚本执行完毕或者显式调用 session_write_close() 来保存会话数据。 在此期间,其他脚本不可以访问同一个会话数据文件。
上述引用参见:Session 的基本用法
为了证明这段话,我们创建一下 2 个文件:
文件:session1.php
<?php session_start(); sleep(5); var_dump($_SESSION); ?>
文件:session2.php
<?php session_start(); var_dump($_SESSION); ?>
在同一个浏览器中,先访问 http://127.0.0.1/session1.php,然后在当前浏览器新的标签页立刻访问 http://127.0.0.1/session2.php。实验发现,session1.php 等了 5 秒钟才有输出,而 session2.php 也等到了将近 5 秒才有输出。而单独访问 session2.php 是秒开的。在一个浏览器中访问 session1.php,然后立刻在另外一个浏览器中访问 session2.php。结果是 session1.php 等待 5 秒钟有输出,而 session2.php 是秒开的。
分析一下造成这个现象的原因:上面例子中,默认使用 Cookie 来传递 session_id,而且 Cookie 的作用域是相同。这样,在同一个浏览器中访问这 2 个地址,提交给服务器的 session_id 就是相同的(这样才能标记访问者,这是我们期望的效果)。当访问 session1.php 时,PHP 根据提交的 session_id,在服务器保存 Session 文件的路径(默认为 /tmp,通过 php.ini 中的 session.save_path 或者函数 session_save_path() 来修改)中找到了对应的 Session 文件,并对其加锁。如果不显式调用 session_write_close(),那么直到当前 PHP 脚本执行完毕才会释放文件锁。如果在脚本中有比较耗时的操作(比如例子中的 sleep(5)),那么另一个持有相同 session_id 的请求由于文件被锁,所以只能被迫等待,于是就发生了请求阻塞的情况。
既然如此,在使用完 Session 后,立刻显示调用 session_write_close() 是不是就解决问题了哩?比如上面例子中,在 sleep(5) 前面调用 session_write_close()。
确实,这样 session2.php 就不会被 session1.php 所阻塞。但是,显示调用了 session_write_close() 就意味着将数据写到文件中并结束当前会话。那么,在后面代码中要使用 Session 时,必须重新调用 session_start()。
例如:
<?php session_start(); $_SESSION['name'] = 'Jing'; var_dump($_SESSION); session_write_close(); sleep(5); session_start(); $_SESSION['name'] = 'Mr.Jing'; var_dump($_SESSION); ?>
官方给出的方案:
对于大量使用 Ajax 或者并发请求的网站而言,这可能是一个严重的问题。 解决这个问题最简单的做法是如果修改了会话中的变量, 那么应该尽快调用 session_write_close() 来保存会话数据并释放文件锁。 还有一种选择就是使用支持并发操作的会话保存管理器来替代文件会话保存管理器。
我推荐的方式是使用 Redis 作为 Session 的处理器。
Session 数据是什么时候被删除的
这是一道经常被面试官问起的问题。
先看看官方手册中的说明:
session.gc_maxlifetime 指定过了多少秒之后数据就会被视为"垃圾"并被清除。 垃圾搜集可能会在 session 启动的时候开始( 取决于 session.gc_probability 和 session.gc_divisor)。 session.gc_probability 与 session.gc_divisor 合起来用来管理 gc(garbage collection 垃圾回收)进程启动的概率。此概率用 gc_probability/gc_divisor 计算得来。例如 1/100 意味着在每个请求中有 1% 的概率启动 gc 进程。session.gc_probability 默认为 1,session.gc_divisor 默认为 100。
继续用我上面那个不太恰当的比方吧:如果我们把物品放在超市的储物箱中而不取走,过了很久(比如一个月),那么保安就要清理这些储物箱中的物品了。当然并不是超过期限了保安就一定会来清理,也许他懒,又或者他压根就没有想起来这件事情。
再看看两段手册的引用:
如果使用默认的基于文件的会话处理器,则文件系统必须保持跟踪访问时间(atime)。Windows FAT 文件系统不行,因此如果必须使用 FAT 文件系统或者其他不能跟踪 atime 的文件系统,那就不得不想别的办法来处理会话数据的垃圾回收。自 PHP 4.2.3 起用 mtime(修改时间)来代替了 atime。因此对于不能跟踪 atime 的文件系统也没问题了。
GC 的运行时机并不是精准的,带有一定的或然性,所以这个设置项并不能确保旧的会话数据被删除。某些会话存储处理模块不使用此设置项。
对于这种删除机制,我是存疑的。
比如 gc_probability/gc_divisor 设置得比较大,或者网站的请求量比较大,那么 GC 进程启动就会比较频繁。
还有,GC 进程启动后都需要遍历 Session 文件列表,对比文件的修改时间和服务端的当前时间,判断文件是否过期而决定是否删除文件。
这也是我觉得不应该使用 PHP 自带的 files 型 Session 处理器的原因。而 Redis 或 Memcached 天生就支持 key/value 过期机制的,用于作为会话处理器很合适。或者自己实现一个基于文件的处理器,当根据 session_id 获取对应的单个 Session 文件时判断文件是否过期。
为什么重启浏览器后 Session 数据就取不到了
session.cookie_lifetime 以秒数指定了发送到浏览器的 cookie 的生命周期。值为 0 表示"直到关闭浏览器"。默认为 0。
其实,并不是 Session 数据被删除(也有可能是,概率比较小,参见上一节)。只是关闭浏览器时,保存 session_id 的 Cookie 没有了。也就是你弄丢了打开超市储物箱的钥匙(session_id)。
同理,浏览器 Cookie 被手动清除或者其他软件清除也会造成这个结果。
为什么浏览器开着,我很久没有操作就被登出了
这个是称为“防呆”,为了保护用户账户安全的。
这个小节放进来,是因为这个功能的实现可能和 Session 的删除机制有关(之所以说是可能,是因为这个功能不一定要借住 Session 实现,用 Cookie 也同样可以实现)。
说简单一点,就是长时间没有操作,服务端的 Session 文件过期被删除了。
一个有意思的事情
在我试验的过程中,发现了小有意思的事情:我把 GC 启动的概率设置为 100%。如果只有一个访问者请求,该访问者即使过了很久(超过了过期时间)后才发起第二次请求,那么 Session 数据也还是存在的('session.save_path' 目录下面的 Session 文件存在)。是的,明明就超过了过期时间,却没有被 GC 删除。这时,我用另外一个浏览器访问时(相对于另一个访问者),这次请求生成了新的 Session 文件,而上一个浏览器请求生成的那个 Session 文件终于没有了(之前那个 Session 文件在 'session.save_path' 目录下面的消失了)。
还有,发现 Session 文件被删除后,再次请求,还是会生成和之前文件名相同的 Session 文件(因为浏览器并没有关闭,再次请求发送的 session_id 是相同的,所以重新生成的 Session 文件的文件名还是一样的)。但是,我不理解的是:这个重新出现的文件的创建时间竟然是第一次的那个创建时间,难道它是从回收站中回来的?(确实,我做这个试验时是在 window 下进行的)
我猜测的原因是这样:当启动会话后,PHP 根据 session_id 找到并打开了对应的 Session 文件,然后才启动 GC 进程。GC 进程就只检查除了当前这个 Session 文件外的其他文件,发现过期的就干掉。所有,即使当前这个 Session 文件已经过期了,GC 也没有删除它。
我认为这个不合理的。
由于发生这种情况影响也不大(毕竟线上请求很多,当前请求的过期文件被其他请求唤起的 GC 干掉的可能性是比较大的),我没有信心去看 PHP 源代码,我并不在线上使用 PHP 自带的 files 型 Session 处理器。所以,这个问题我就没有深入研究了,请谅解。
<?php
// 过期时间设置为 30 秒
ini_set('session.gc_maxlifetime', '30');
// GC 启动概率设置为 100%
ini_set('session.gc_probability', '100');
ini_set('session.gc_divisor', '100');
session_start();
$_SESSION['name'] = 'Jing';
var_dump($_SESSION);
?>
如何设置一个严格30分钟过期的Session
第一种回答
那么, 最常见的一种回答是: 设置Session的过期时间, 也就是session.gc_maxlifetime, 这种回答是不正确的, 原因如下:
1. 首先, 这个PHP是用一定的概率来运行session的gc的, 也就是session.gc_probability和session.gc_divisor(介绍参看 深入理解PHP原理之Session Gc的一个小概率Notice), 这个默认的值分别是1和100, 也就是有1%的机会, PHP会在一个Session启动时, 运行Session gc. 不能保证到30分钟的时候一定会过期.
2. 那设置一个大概率的清理机会呢? 还是不妥, 为什么? 因为PHP使用stat Session文件的修改时间来判断是否过期, 如果增大这个概率一来会降低性能, 二来, PHP使用”一个”文件来保存和一个会话相关的Session变量, 假设我5分钟前设置了一个a=1的Session变量, 5分钟后又设置了一个b=2的Seesion变量, 那么这个Session文件的修改时间为添加b时刻的时间, 那么a就不能在30分钟的时候, 被清理了. 另外还有下面第三个原因.
3. PHP默认的(Linux为例), 是使用/tmp 作为Session的默认存储目录, 并且手册中也有如下的描述:
Note: 如果不同的脚本具有不同的 session.gc_maxlifetime 数值但是共享了同一个地方存储会话数据,则具有最小数值的脚本会清理数据。此情况下,与 session.save_path 一起使用本指令。
也就是说, 如果有俩个应用都没有指定自己独立的save_path, 一个设置了过期时间为2分钟(假设为A), 一个设置为30分钟(假设为B), 那么每次当A的Session gc运行的时候, 就会同时删除属于应用B的Session files.
所以, 第一种答案是不”完全严格”正确的.
第二种答案
还有一种常见的答案是: 设置Session ID的载体, Cookie的过期时间, 也就是session.cookie_lifetime. 这种回答也是不正确的, 原因如下:
这个过期只是Cookie过期, 换个说法这点就考察Cookie和Session的区别, Session过期是服务器过期, 而Cookie过期是客户端(浏览器)来保证的, 即使你设置了Cookie过期, 这个只能保证标准浏览器到期的时候, 不会发送这个Cookie(包含着Session ID), 而如果通过构造请求, 还是可以使用这个Session ID的值.
第三种答案
使用memcache, redis等, okey, 这种答案是一种正确答案. 不过, 很显然出题者肯定还会接着问你, 如果只是使用PHP呢?
第四种答案
当然, 面试不是为了难道你, 而是为了考察思考的周密性. 在这个过程中我会提示出这些陷阱, 所以一般来说, 符合题意的做法是:
1. 设置Cookie过期时间30分钟, 并设置Session的lifetime也为30分钟.
2. 自己为每一个Session值增加Time stamp.
3. 每次访问之前, 判断时间戳.
最后, 有同学问, 为什么要设置30分钟的过期时间: 这个, 首先这是为了面试, 第二, 实际使用场景的话, 比如30分钟就过期的优惠??
为什么不能用memcached存储Session
Titas Norkūnas是DevOps咨询服务提供商Bear Mountain的联合创始人。由于看到Ruby/Rails社区忽略了Dormando那两篇文章所指出的问题,所以他近日撰文对此进行了进一步的阐述。他认为问题的根本在于,memcached是一个设计用于缓存数据而不是存储数据的系统,因此不应该用于存储Session。
对于Dormando的那两篇文章,他认为第一篇文章给出的原因很容易理解,而人们经常会对第二篇文章给出的原因认识不足。因此他对这个原因进行了详细地阐述:
Memcached使用“最近最少使用(LRU)”算法回收缓存。但memcached的LRU算法针对每个slab类执行,而不是针对整体。
这意味着,如果所有Session的大小大致相同,那么它们会分成两三个slab类。所有其它大小大致相同的数据也会放入同一些slab,与Session争用存储空间。一旦slab满了,即使更大的slab中还有空间,数据也会被回收,而不是放入更大的slab中……在特定的slab中,Session最老的用户将会掉线。用户将会开始随机掉线,而最糟糕的是,你很可能甚至都不会注意到它,直至用户开始抱怨……
另外,Norkūnas提到,如果Session中增加了新数据,那么Session变大也可能会导致掉线问题出现。
有人提出将Session和其它数据分别使用单独的memcached缓存。不过,由于memcached的LRU算法是局部的,那种方式不仅导致内存使用率不高,而且也无法消除用户因为Session回收而出现随机掉线的风险。
如果读者非常希望借助memcached提高Session读取速度,那么可以借鉴Norkūnas提出的memcached+RDBMS(在有些情况下,NoSQL也可以)的模式:
当用户登录时,将Session “set”到memcached,并写入数据库;
在Session中增加一个字段,标识Session最后写入数据库的时间;
每个页面加载的时候,优先从memcached读取Session,其次从数据库读取;
每加载N页或者Y分钟后,再次将Session写入数据库;
从数据库中获取过期Session,优先从memcached中获取最新数据。
百度链接提交三种方式:
1、主动推送:最为快速的提交方式,推荐您将站点当天新产出链接立即通过此方式推送给百度,以保证新链接可以及时被百度收录。
2、sitemap:您可以定期将网站链接放到sitemap中,然后将sitemap提交给百度。百度会周期性的抓取检查您提交的sitemap,对其中的链接进行处理,但收录速度慢于主动推送。
3、手工提交:一次性提交链接给百度,可以使用此种方式。
下面介绍使用curl主动推送链接的方式PHP示例,使用curl扩展:
$urls = array(
'http://www.example.com/1.html',
'http://www.example.com/2.html',
);
$api = 'http://data.zz.baidu.com/urls?site=www.dayecn.com&token=Db0ZoYUOwUyEp87Z';
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => implode("\n", $urls),
CURLOPT_HTTPHEADER => array('Content-Type: text/plain'),
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
echo $result;
首先要在百度站长平台验证站点,然后获取token密钥,才有权限推送url给百度。百度站长平台:http://zhanzhang.baidu.com
可以在发布一篇文章的时候就把这篇文章的url推送给百度站长平台,或者批量推送,通过返回的$result状态判断推送是否成功,返回的状态码说明:
推送成功
状态码为200,可能返回以下字段:
字段 是否必选 参数类型 说明
success 是 int 成功推送的url条数
remain 是 int 当天剩余的可推送url条数
not_same_site 否 array 由于不是本站url而未处理的url列表
not_valid 否 array 不合法的url列表
成功返回示例:
{
"remain":4999998,
"success":2,
"not_same_site":[],
"not_valid":[]
}
推送失败
状态码为4xx,返回字段有:
字段 是否必传 类型 说明
error 是 int 错误码,与状态码相同
message 是 string 错误描述
失败返回示例:
{
"error":401,
"message":"token is not valid"
}
php语言本身不支持多线程,所以开发爬虫程序效率并不高,借助Curl Multi 它可以实现并发多线程的访问多个url地址。用 Curl Multi 多线程下载文件代码:
代码1:将获得的代码直接写入某个文件
<?php
$urls =array(
'http://www.111cn.net/',
'http://www.baidu.com/',
);// 设置要抓取的页面URL
$save_to='test.txt'; // 把抓取的代码写入该文件
$st =fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i =>$url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT,"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st);// 设置将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
}// 初始化
do {
curl_multi_exec($mh,$active);
}while ($active); // 执行
foreach ($urls as $i =>$url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}// 结束清理
curl_multi_close($mh);
fclose($st);
?>
代码2:将获得的代码先放入变量,再写入某个文件
<?php
$urls =array(
'http://m.111cn.net/',
'http://www.111cn.net/',
'http://www.163.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st =fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i =>$url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT,"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 设置不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
}while ($active);
foreach ($urls as $i =>$url) {
$data = curl_multi_getcontent($conn[$i]);// 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件。当然,也可以不写入文件,比如存入数据库
}// 获得数据变量,并写入文件
foreach ($urls as $i =>$url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
?>
curl抓取网页中文乱码的解决方法
function ppost($url,$data,$ref){ // 模拟提交数据函数
$curl = curl_init(); // 启动一个CURL会话
curl_setopt($curl, CURLOPT_URL, $url); // 要访问的地址
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, 0); // 对认证证书来源的检查
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, 1); // 从证书中检查SSL加密算法是否存在
curl_setopt($curl, CURLOPT_USERAGENT, $_SERVER['HTTP_USER_AGENT']); // 模拟用户使用的浏览器
curl_setopt($curl, CURLOPT_FOLLOWLOCATION, 1); // 使用自动跳转
curl_setopt($curl, CURLOPT_REFERER, $ref);
curl_setopt($curl, CURLOPT_POST, 1); // 发送一个常规的Post请求
curl_setopt($curl, CURLOPT_POSTFIELDS, $data); // Post提交的数据包
curl_setopt($curl, CURLOPT_COOKIEFILE,$GLOBALS ['cookie_file']); // 读取上面所储存的Cookie信息
curl_setopt($curl, CURLOPT_COOKIEJAR, $GLOBALS['cookie_file']); // 存放Cookie信息的文件名称
curl_setopt($curl, CURLOPT_HTTPHEADER,array('Accept-Encoding: gzip, deflate'));
curl_setopt($curl, CURLOPT_ENCODING, 'gzip,deflate');这个是解释gzip内容.................
curl_setopt($curl, CURLOPT_TIMEOUT, 30); // 设置超时限制防止死循环
curl_setopt($curl, CURLOPT_HEADER, 0); // 显示返回的Header区域内容
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1); // 获取的信息以文件流的形式返回
$tmpInfo = curl_exec($curl); // 执行操作
if (curl_errno($curl)) {
echo 'Errno'.curl_error($curl);
}
curl_close($curl); // 关键CURL会话
return $tmpInfo; // 返回数据
}
按地区搜索:
http://api.map.baidu.com/geosearch/v3/local?region=%E5%8E%A6%E9%97%A8&ak=pWiNP7mGeptewlpldEdv3Ur3&geotable_id=*****
按位置中心点搜索(距离中心位置1800米):
http://api.map.baidu.com/geosearch/v3/nearby?ak=pWiNP7mGeptewlpldEdv3Ur3&geotable_id=***&location=118.145572,24.49264&radius=1800
程序代码如下
首先要把数据录入到百度云数据库
用接口提交位置信息,坐标经纬度到百度lbs云数据库。
百度提供可视化的LBS云数据库管理:
http://lbsyun.baidu.com/datamanager/datamanage
已下是我写的一个提交数据接口:
这里是提交或更新一个lbs数据。
function ptolbs($data,$lbsid){
if($lbsid<=0){
$purl = 'http://api.map.baidu.com/geodata/v3/poi/create';
}else{
$data['id']=$lbsid;
$purl = "http://api.map.baidu.com/geodata/v3/poi/update";
}
$data['ak']="pWiNP7mGeptewlpldEdv3Ur3";
$data['geotable_id']="***";//你的数据库ID
$data['coord_type']="3";
$re = curlpost($purl,$data);
$re = json_decode($re,true);
if($re["status"]==0){
$lbsid =$re['id'];
}else{
$lbsid = -1;
}
return $lbsid;
}
function curlpost($c_url,$data)
{
$curl = curl_init(); // 启动一个CURL会话
curl_setopt($curl, CURLOPT_URL, $c_url); // 要访问的地址
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, 0); // 对认证证书来源的检查
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, 1); // 从证书中检查SSL加密算法是否存在
curl_setopt($curl, CURLOPT_USERAGENT, $_SERVER['HTTP_USER_AGENT']); // 模拟用户使用的浏览器
// curl_setopt($curl, CURLOPT_FOLLOWLOCATION, 1); // 使用自动跳转
curl_setopt($curl, CURLOPT_AUTOREFERER, 1); // 自动设置Referer
curl_setopt($curl, CURLOPT_POST, 1); // 发送一个常规的Post请求
curl_setopt($curl, CURLOPT_POSTFIELDS, $data); // Post提交的数据包
curl_setopt($curl, CURLOPT_TIMEOUT, 30); // 设置超时限制防止死循环
curl_setopt($curl, CURLOPT_HEADER, 0); // 显示返回的Header区域内容
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1); // 获取的信息以文件流的形式返回
$tmpInfo = curl_exec($curl); // 执行操作
if (curl_errno($curl)) {
echo 'Errno'.curl_error($curl);//捕抓异常
}
curl_close($curl); // 关闭CURL会话
return $tmpInfo; // 返回数据
}
原理很简单就是通过我们申请的key 带在curl中post给百度api,然后百度返回查询对应的坐标与数据给我们。
相关文章
- 本文给大家分享C#连接SQL数据库和查询数据功能的操作技巧,本文通过图文并茂的形式给大家介绍的非常详细,需要的朋友参考下吧...2021-05-17
- 最基础的对数据的增加删除修改操作实例,菜鸟们收了吧...2013-09-26
- 这篇文章主要介绍了解决Mybatis 大数据量的批量insert问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-01-09
Antd-vue Table组件添加Click事件,实现点击某行数据教程
这篇文章主要介绍了Antd-vue Table组件添加Click事件,实现点击某行数据教程,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-11-17- 这篇文章主要介绍了详解如何清理redis集群的所有数据,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2021-02-18
- 这篇文章主要介绍了vue 获取到数据但却渲染不到页面上的解决方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-11-19
- 在php中解析xml文档用专门的函数domdocument来处理,把json在php中也有相关的处理函数,我们要把数据xml 数据存到一个数据再用json_encode直接换成json数据就OK了。...2016-11-25
- 这篇文章主要介绍了mybatis-plus 处理大数据插入太慢的解决,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-12-18
- 神马是“解释器模式”?先翻开《GOF》看看Definition:给定一个语言,定义它的文法的一种表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子。在开篇之前还是要科普几个概念: 抽象语法树: 解释器模式并未解释如...2014-06-07
- 这篇文章主要为大家介绍了JavaScript设计模式中的装饰者模式,对JavaScript设计模式感兴趣的小伙伴们可以参考一下...2016-01-21
- 这篇文章主要介绍了Postgresl 如何选择正确的关闭模式,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-01-18
- 这篇文章主要介绍了postgresql数据添加两个字段联合唯一的操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-02-04
Vue生命周期activated之返回上一页不重新请求数据操作
这篇文章主要介绍了Vue生命周期activated之返回上一页不重新请求数据操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-07-26- 很多集成的PHP环境(PHPnow WAMP Appserv等)自带的MySQL貌似都没有开启MySQL的严格模式,何为MySQL的严格模式,简单来说就是MySQL自身对数据进行严格的校验(格式、长度、类型等),比如一个整型字段我们写入一个字符串类型的数...2013-10-04
- 这篇文章主要介绍了c# socket网络编程,server端接收,client端发送数据,大家参考使用吧...2020-06-25
- 这篇文章主要介绍了解决vue watch数据的方法被调用了两次的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-11-07
- 这篇文章主要介绍了vue 数据(data)赋值问题的解决方案,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-29
- 这篇文章主要介绍了Python3 常用数据标准化方法详解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-24
- 这篇文章主要为大家详细介绍了node.js从数据库获取数据的具体代码,nodejs可以获取具体某张数据表信息,感兴趣的朋友可以参考一下...2016-05-09
- 下面将把C#里实现IDispose模式的代码展现出来,大家一起来学习一下,它的使用场合也很多的,当我们手动对网站,数据库作封装时,都会用的到...2020-06-25