pandas 读取excel文件的操作代码
一 read_excel() 的基本用法
import pandas as pd file_name = 'xxx.xlsx' pd.read_excel(file_name)
二 read_excel() 的常用的参数:
io: excel路径 可以是文件路径, 类文件对象, 文件路径对象等。
sheet_name=0: 访问指定excel某张工作表。sheet_name可以是str, int, list 或 None类型, 默认值是0。
str类型 是直接指定工作表的名称
int类型 是指定从0开始的工作表的索引, 所以sheelt_name默认值是0,即第一个工作表。
list类型 是多个索引或工作表名构成的list,指定多个工作表。
None类型, 访问所有的工作表
sheet_name=0: 得到的是第1个sheet的DataFrame类型的数据
sheet_name=2: 得到的是第3个sheet的DataFrame类型的数据
sheet_name=‘Test1': 得到的是名为'Test1'的sheet的DataFrame类型的数据
sheet_name=[0, 3, ‘Test5']: 得到的是第1个,第4个和名为Test5 的工作表作为DataFrame类型的数据的字典。
header=0:header是标题行,通过指定具体的行索引,将该行作为数据的标题行,也就是整个数据的列名。默认首行数据(0-index)作为标题行,如果传入的是一个整数列表,那这些行将组合成一个多级列索引。没有标题行使用header=None。
name=None: 传入一列类数组类型的数据,用来作为数据的列名。如果文件数据不包含标题行,要显式的指出header=None。
skiprows:int类型, 类列表类型或可调函数。 要跳过的行号(0索引)或文件开头要跳过的行数(int)。如果可调用,可调用函数将根据行索引进行计算,如果应该跳过行则返回True,否则返回False。一个有效的可调用参数的例子是lambda x: x in [0, 1, 2]。
skipfooter=0: int类型, 默认0。自下而上,从尾部指定跳过行数的数据。
usecols=None: 指定要使用的列,如果没有默认解析所有的列。
index_col=None: int或元素都是int的列表, 将某列的数据作为DataFrame的行标签,如果传递了一个列表,这些列将被组合成一个多索引,如果使用usecols选择的子集,index_col将基于该子集。
squeeze=False, 布尔值,默认False。 如果解析的数据只有一列,返回一个Series。
dtype=None: 指定某列的数据类型,可以使类型名或一个对应列名与类型的字典,例 {‘A': np.int64, ‘B': str}
nrows=None: int类型,默认None。 只解析指定行数的数据。
三 示例
如图是演示使用的excel文件,它包含5张工作表。
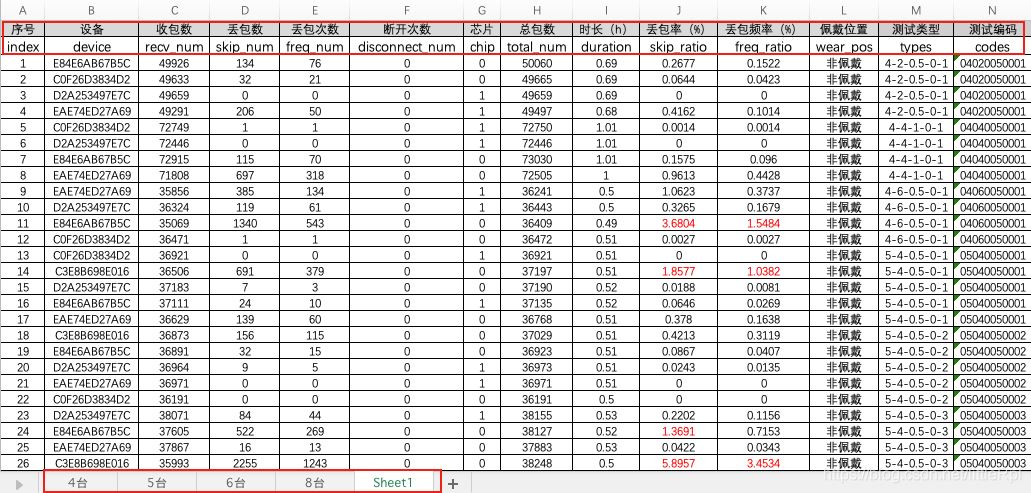
1. IO:路径
举一个IO为文件对象的例子, 有些时候file文件路径的包含较复杂的中文字符串时,pandas 可能会解析文件路径失败,可以使用文件对象来解决。
file = 'xxxx.xlsx'
f = open(file, 'rb')
df = pd.read_excel(f, sheet_name='Sheet1')
f.close() # 没有使用with的话,记得要手动释放。
# ------------- with模式 -------------------
with open(file, 'rb') as f:
df = pd.read_excel(f, sheet_name='Sheet1')
2. sheet_name:指定工作表名
sheet_name=‘Sheet', 指定解析名为"Sheet1"的工作表。返回一个DataFrame类型的数据。
df = pd.read_excel(file, sheet_name='Sheet1')
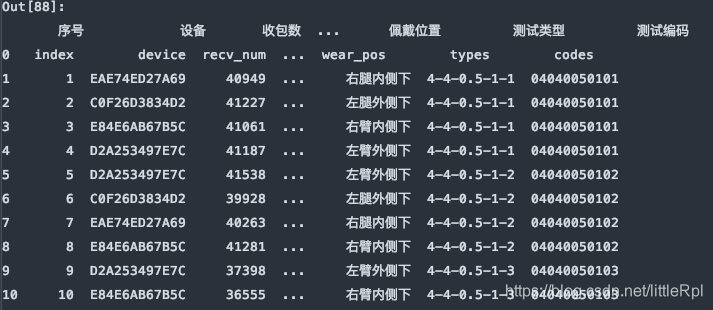
sheet_name=[0, 1, ‘Sheet1'], 对应的是解析文件的第1, 2张工作表和名为"Sheet1"的工作表。它返回的是一个有序字典。结构为{name:DataFrame}这种类型。
df_dict = pd.read_excel(file, sheet_name=[0,1,'Sheet1'])
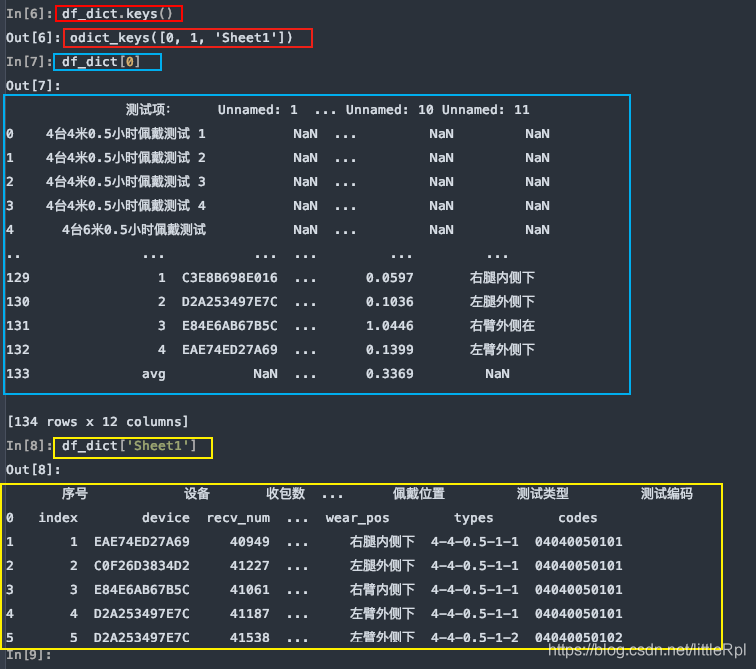
sheet_name=None 会解析该文件中所有的工作表,返回一个同上的字典类型的数据。
df_dict = pd.read_excel(file, sheet_name=None)

3. header :指定标题行
header是用来指定数据的标题行,也就是数据的列名的。本文使用的示例文件具有中英文两行列名,默认header=0是使用第一行数据作为数据的列名。
df_dict = pd.read_excel(file, sheet_name='Sheet1')
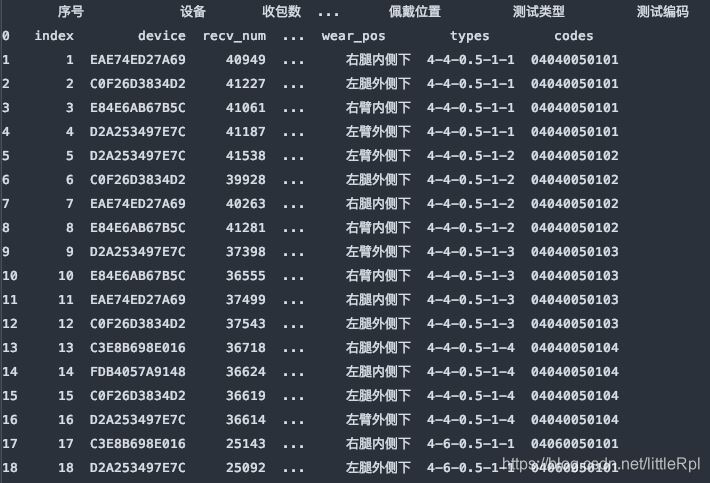
header=1, 使用指定使用第二行的英文列名。
df_dict = pd.read_excel(file, sheet_name='Sheet1', header=1)
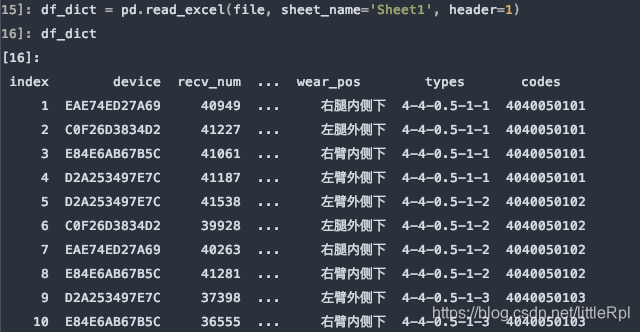
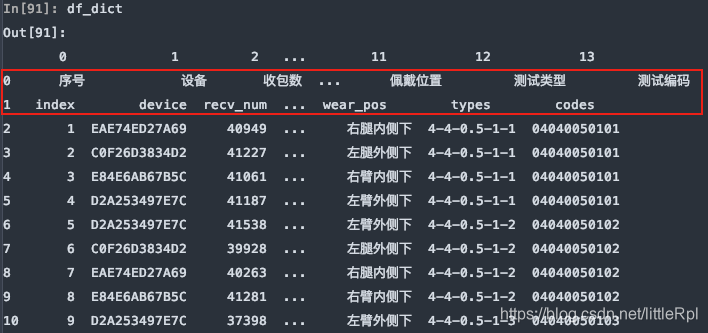
需要注意的是,如果不行指定任何行作为列名,或数据源是无标题行的数据,可以显示的指定header=None来表明不使用列名。
df_dict = pd.read_excel(file, sheet_name='Sheet1', header=None)
4. names: 指定列名
指定数据的列名,如果数据已经有列名了,会替换掉原有的列名。
df = pd.read_excel(file, sheet_name='Sheet1', names=list('123456789ABCDE'))
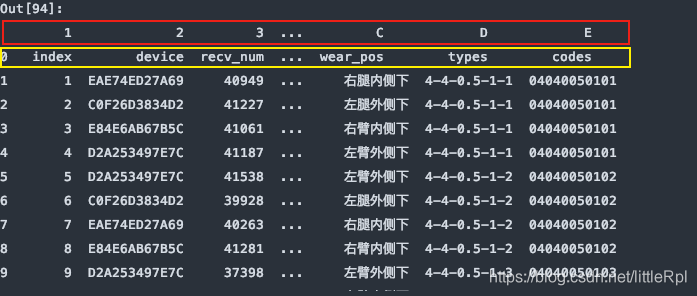
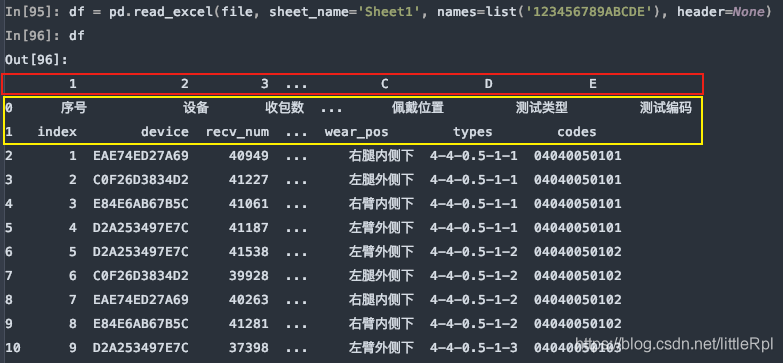
上图是header=0默认第一行中文名是标题行,最后被names给替换了列名,如果只想使用names,而又对源数据不做任何修改,我们可以指定header=None
df = pd.read_excel(file, sheet_name='Sheet1', names=list('123456789ABCDE'), header=None)
5. index_col: 指定列索引
df = pd.read_excel(file, sheet_name='Sheet1', header=1, index_col=0)
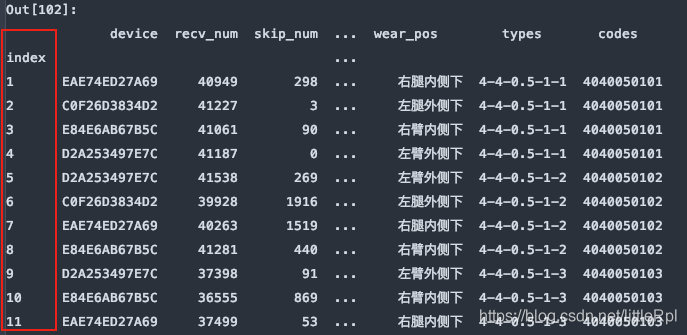
6. skiprows:跳过指定行数的数据
df = pd.read_excel(file, sheet_name='Sheet1', skiprows=0)
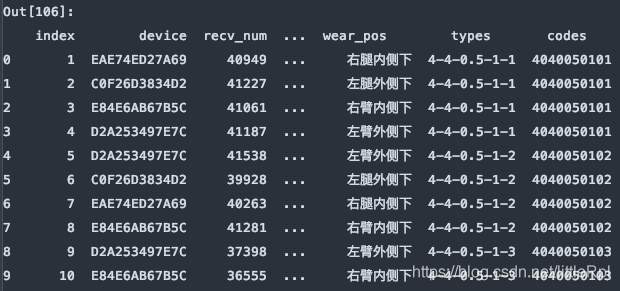
df = pd.read_excel(file, sheet_name='Sheet1', skiprows=[1,3,5,7,9,])
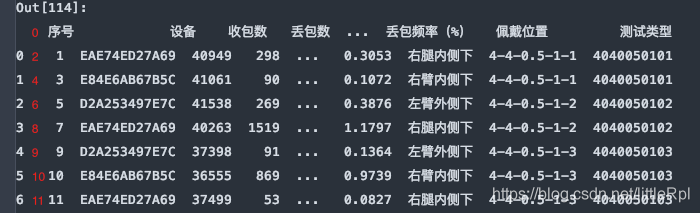
header与skiprows在有些时候效果相同,例skiprows=5和header=5。因为跳过5行后就是以第六行,也就是索引为5的行默认为标题行了。需要注意的是skiprows=5的5是行数,header=5的5是索引为5的行。
df = pd.read_excel(file, sheet_name='Sheet1', header=5)
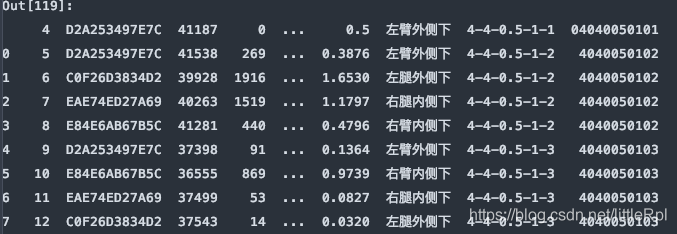
df = pd.read_excel(file, sheet_name='Sheet1', skiprows=5)
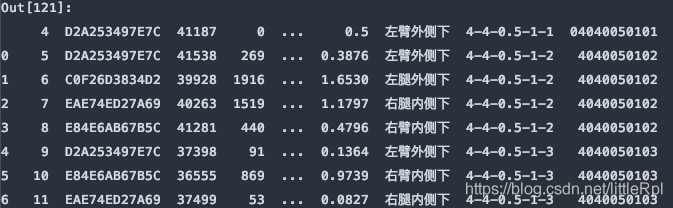
7. skipfooter:省略从尾部的行数据
原始的数据有47行,如下图所示:
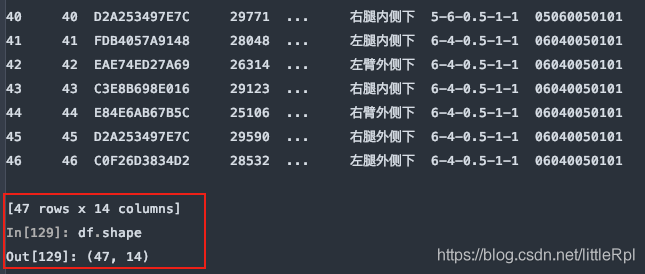
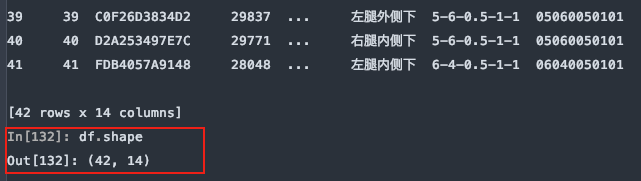
从尾部跳过5行:
df = pd.read_excel(file, sheet_name='Sheet1', skipfooter=5)
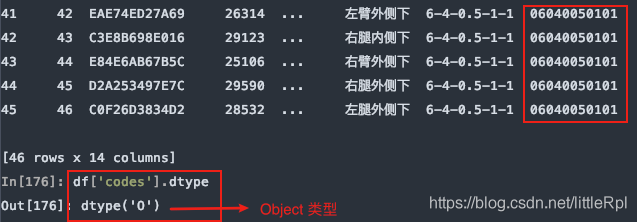
8.dtype 指定某些列的数据类型
示例数据中,测试编码数据是文本,而pandas在解析的时候自动转换成了int64类型,这样codes列的首位0就会消失,造成数据错误,如下图所示
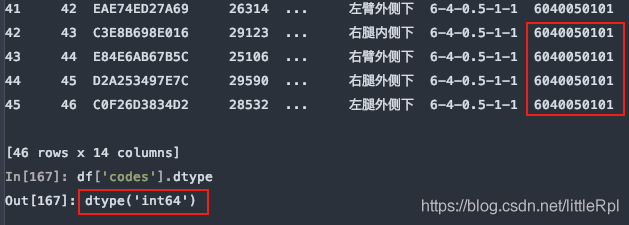
指定codes列的数据类型:
df = pd.read_excel(file, sheet_name='Sheet1', header=1, dtype={'codes': str})
到此这篇关于pandas 读取excel文件的文章就介绍到这了,更多相关pandas 读取excel文件内容请搜索猪先飞以前的文章或继续浏览下面的相关文章希望大家以后多多支持猪先飞!
原文出处:https://blog.csdn.net/littleRpl/article/details/113996603
相关文章
pandas pd.read_csv()函数中parse_dates()参数的用法说明
这篇文章主要介绍了pandas pd.read_csv()函数中parse_dates()参数的用法说明,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-05- 今天小编就为大家分享一篇Pandas实现DataFrame按行求百分数(比例数),具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-05-09
- 本文主要介绍了python使用pandas按照行数分割表格,文中通过示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下...2021-08-13
- 这篇文章主要介绍了解决python3安装pandas出错的问题,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教...2021-05-20
- 比较操作是很简单的基础知识,不过Pandas中的比较操作有一些特殊的点,本文介绍的非常详细,对正在学习python的小伙伴们很有帮助.需要的朋友可以参考下...2021-05-20
- 这篇文章主要介绍了用pandas划分数据集实现训练集和测试集,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-07-20
- 这篇文章主要介绍了pandas 实现将两列中的较大值组成新的一列,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-26
- pandas 读取excel文件使用的是 read_excel方法。本文将详细解析read_excel方法的常用参数,以及实际的使用示例,感兴趣的朋友跟随小编一起看看吧...2021-11-01
解决python pandas读取excel中多个不同sheet表格存在的问题
这篇文章主要介绍了解决python pandas读取excel中多个不同sheet表格存在的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-07-14- 笔者最近正在学习Pandas数据分析,将自己的学习笔记做成一套系列文章。本节主要记录Pandas中使用stack和pivot实现数据透视。感兴趣的小伙伴们可以参考一下...2021-09-05
Pandas.DataFrame转置的实现 <font color=red>原创</font>
这篇文章主要介绍了Pandas.DataFrame转置的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2021-03-09- 这篇文章主要介绍了对python pandas中 inplace 参数的理解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-06-28
- 这篇文章主要介绍了pandas 实现某一列分组,其他列合并成list的案例。具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2021-03-26
- 今天给大家带来的是关于Python的相关知识,文章围绕着Pandas常用函数方法展开,文中有非常详细的介绍及代码示例,需要的朋友可以参考下...2021-06-16
.NET中读取Excel文件的数据及excelReader应用
轻量,快速的C#编写的库读取Microsoft Excel文件,这对读取大量excel文件的朋友们很有帮助而且可以学习下ExcelDataReader的应用,感兴趣的朋友可以了解下,或许对你有所帮助...2021-09-22- 今天小编就为大家分享一篇Pandas 解决dataframe的一列进行向下顺移问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧...2020-05-09
- 这篇文章主要介绍了python 用pandas实现数据透视表功能的方法,帮助大家更好的理解和使用python,感兴趣的朋友可以了解下...2020-12-21
- 这篇文章主要介绍了基于pandas向csv添加新的行和列,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下...2020-05-26
- 这篇文章主要介绍了快速解释如何使用pandas的inplace参数的使用,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧...2020-07-23
- 时间偏移就是在指定时间往前推或者往后推一段时间,即加减一段时间之后的时间,本文使用Python实现,感兴趣的可以了解一下...2021-08-08